
Inference Scaling Law: AGI Is Coming Faster Than I Realized

Author’s Note: This post is free because I think it’s a super important topic that is overlooked. If you want to support this newsletter so I can put more time into creating better-quality articles on AI augmentation, please consider becoming a paid subscriber.
The rapid advancement of AI is about to change the world as we know it. The more research I do, the more my conviction increases.
To navigate this transformative era, it's crucial to understand two fundamental aspects of AI:
Its incredible potential
Its accelerating timeline
Why This Understanding Of AI Matters
Your grasp of AI's potential and timeline directly shapes your strategies for the future. If AI were progressing slowly with limited impact, it might not warrant much attention. However, if it were evolving at breakneck speed with transformative power, it would demand a radical shift in your approach to life and work.
The AI Scaling Laws and Moore's Law
The importance of understanding timelines and capabilities is why I’ve dedicated so much time to understanding:
These principles shed light on the significance of the recent launch of ChatGPT o1-preview, OpenaAI’s most advanced model. This model announcement is a bigger deal than people think.
ChatGPT o1-preview: A Game Changer
Traditional AI Scaling: The Old Way
Traditionally, AI got smarter by:
Using more computing power
Increasing model size (parameters)
Training on more data
This scaling happened during the training phase, before the AI was ready to use.
The O1-Preview Breakthrough: Scaling During Use
ChatGPT O1-Preview introduces a game-changing approach:
Scaling happens during the inference phase (when you're actually using the AI)
The AI "thinks" before answering, like a human taking time to ponder
How It Works
You ask a question
Instead of answering immediately, the AI spends time reasoning (10-100 seconds)
This extra "thinking time" leads to more insightful answers
The New Scaling Law: More Compute = Smarter AI
As computers get faster and more efficient:
AI can "think" longer for the same cost
Example: What's now 10 minutes of AI thinking could become 10 years in the future
Potential Impact
Tasks that take humans days could be done by AI in seconds
More compute → Longer reasoning time → Smarter, more capable AI
The path to AI agents that go out in the world and do things becomes more feasible.
The Big Picture Implications
Compute is a critical resource to both scaling laws. This is why hundreds of billions of dollars are being spent on more and more advanced chips. According to Jensen Huang, the CEO of the largest chip company in the world (see video below), because of three exponentials (Moore’s Law, Training Scaling Law, Inference Scaling Law), the effective improvement rate of compute is 100,000x per 10-year period. To put the power of compute in context, Sam Altman, CEO of OpenAI, says, “What are the limitations of GPT? “There are many questions as to whether it exists, but I will confidently say ‘no.’” We are confident that there are no limits to the GPT model and that if sufficient computational resources are invested, it will not be difficult to build AGI that surpasses humans.”
AGI may come faster than we think. As my conviction on AI’s timeline and capabilities evolves, I’m spending more and more of my time using and thinking about AI. And, I’m throwing away my long-term strategies, so I can think from AI-first principles and rapidly adapt in a “hyper-change” world.
Other AI Experts Add Context
UPENN Researcher Ethan Mollick gives a solid overview in Scaling: The State of Play in AI:
When the o1-preview and o1-mini models from OpenAI were revealed last week, they took a fundamentally different approach to scaling… o1-preview achieves really amazing performance in narrow areas by using a new form of scaling that happens AFTER a model is trained. It turns out that inference compute - the amount of computer power spent “thinking” about a problem, also has a scaling law all its own. This “thinking” process is essentially the model performing multiple internal reasoning steps before producing an output, which can lead to more accurate responses…
Unlike your computer, which can process in the background, LLMs can only “think” when they are producing words and tokens. We have long known that one of the most effective ways to improve the accuracy of a model is through having it follow a chain of thought (prompting it, for example: first, look up the data, then consider your options, then pick the best choice, finally write up the results) because it forces the AI to “think” in steps. What OpenAI did was get the o1 models to go through just this sort of “thinking” process, producing hidden thinking tokens before giving a final answer. In doing so they revealed another scaling law - the longer a model “thinks,” the better its answer is.
Just like the scaling law for training, this seems to have no limit, but also like the scaling law for training, it is exponential, so to continue to improve outputs, you need to let the AI “think” for ever longer periods of time. It makes the fictional computer in The Hitchhikers Guide to the Galaxy, which needed 7.5 million years to figure out the ultimate answer to the ultimate question, feel more prophetic than a science fiction joke. We are in the early days of the “thinking” scaling law, but it shows a lot of promise for the future.
Jensen Huang, founder and CEO of the largest chip company in the world, Nvidia, explains the significance of AI having more time to think:
Source: T-Mobile
One of the things that Sam [Altman] introduced recently, the reasoning capability of these AIs are going to be so much smarter, but it's going to require so much more computation. And so whereas each one of the prompts today into ChatGPT is a one pass, in the future is going to be hundreds of passes inside, it's going to be reasoning, it's going to be doing reinforcement learning, it's going to be trying to figure out how to create a better answer—reason, a better answer for you. Well, that's the reason why in the Blackwell platform, we improved inference performance by 50 x by improving the inference performance by 50 x that reasoning engine, which now could take up to minutes to answer a particular prompt, could still now respond in seconds. And so this is going to be a great new world. And I'm excited about that.
Jensen Huang explains that the rate of progress in AI is Moore’s Law Squared. That is an improvement rate of 100,000x per 10-year period:
Source: Salesforce Dreamforce conference
When unsupervised learning came along, which allowed us to use language models to create language models which codify human prior knowledge, using that to now learn multi-modality multimodal data. Then from that point forward, the scale was going to be exponential. Now, you know, for for everybody here, this is this is an extraordinary time because in no time in history has computer technology not only, uh, moved faster than Moore's Law. I mean, where Moore's Law, for example, over the course of, uh, over the course of a decade would be about 100 x. Um, we are probably advancing at somewhere near 100. That was our other neighbor in Hawaii, Gordon Moore. Oh, is that right? Great person, great leader, great person. And so we're we're we're at a stage now. We're in an era now where, where we're moving way faster than Moore's Law. And, and um, arguably easily Moore's law squared. And the reason the reason for that, of course, is at every single layer, computers went from CPUs to GPUs, from human engineered software to machine learning software. And and now this feedback loop that allows us to to create new AIS and these new AIS are helping us create new computer systems. And these new computer systems are advancing at such incredible rates, which allows us to create even better AI. Uh, that feedback, that flywheel is really flying now. And so I think I think the, the, uh, the progress that you're going to have with agents over the next year or two is going to be spectacular and surprising.
Ben Thompson, my favorite tech analyst, gives his take on o1-preview’s significance:
Source: Ben Thompson
The other big thing is at inference time when you actually go in and ask a question, it has it's doing something called chain of thought. And it's generating these reasoning tokens. And what seems to be going on is when you ask a question, it solves it multiple times. When it's doing that probabilistic function, the next step isn't just the next token, it's the next sort of technique and format that it has in its training data from, from this sort of process. And it tries a bunch of different sorts of things, and then it sort of ranks, what's the best one that makes sense? And then it works down it. It has some sort of function that's checking it's work as it goes. And then when it's wrong, it sresets and goes back further up the chain and restarts what it's doing now.
This is really fuzzy, exactly how it's working and what it's doing. There's a bunch of tokens that are being generated where it's doing all this, this quote unquote thinking. We're not going to show it to you because, whether it be safety reasons or competitive reasons, because this probably reveals a lot of how it's actually working. But these reasoning tokens let us explore different techniques of solving this problem. Let us sort of catch logical errors as they happen, go back and sort of reset. And it's pretty remarkable.
More compute is actually making it better and more accurate because it can generate more of these reasoning tokens. It can do more exploration of the space. We already knew about scaling laws on the training side. Right. You spend more money, you get more GPUs. You can you can use more data and you'll get more accuracy. This is scaling laws on the inference side, the more compute and the more time the smarter it is. It's like a very direct link. Energy equals intelligence. Like it's in a very sort of direct sort of way when it comes to this on the inference side.
And that's really compelling and interesting for the long run in terms of how you think about the economics. It's really compelling and interesting in terms of like the capabilities sort of of this what it sort of worth. This is setting the stage for other things sort of down the road. What I think is really compelling is now I'm much more on board with a lot of this talk about agents. Right?
The idea I've been skeptical, not skeptical, but not feeling like the agent path wasn't as compelling as people were spinning it up to be. Just because I felt as as amazing as LLMs are, this fundamental reasoning function was, was, was missing. And yes, you could do validation and send it back to do it again. That is a tricky problem. It's not clear how well it scales and you know you're just trying to get it. You're trying to to get it to give you the right answer. Give me the right answer. Give me the right answer. Give me the right answer. This doesn't memorize answers. It memorizes reasoning.
An o1-preview lead researcher shares how results scale with thinking time:
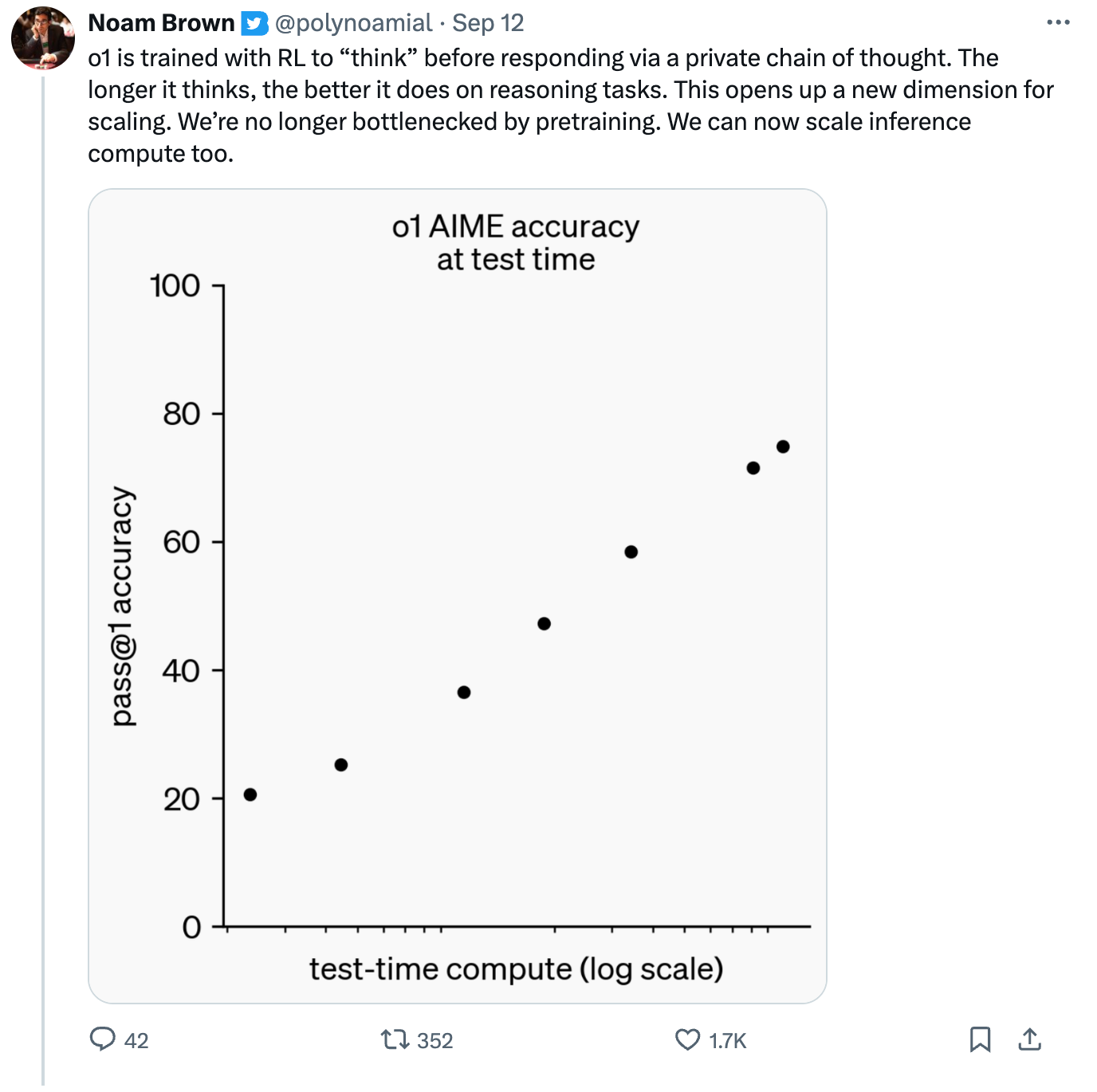
Source: Twitter
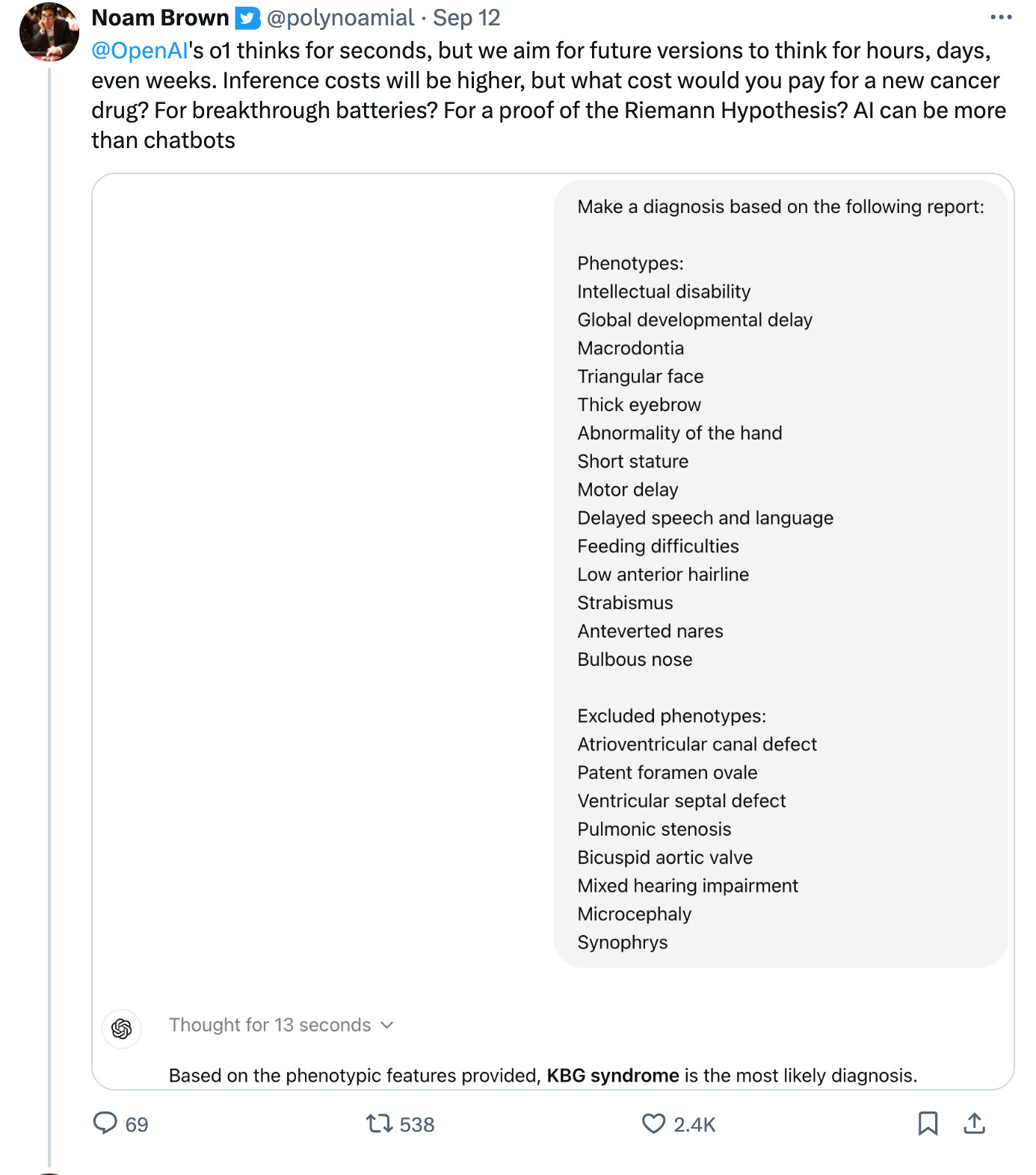
Source: Twitter
The new o1-preview lead researcher makes a pretty shocking admission about AI consciousness:

Thank you Michael for sharing these fascinating insights and trends. You are exciting me to delve deeper into this AI space by opening my eyes and mind
Thank you for your take on the AI industry and their many announcements and launches. Along with the many advances in ChatGPT and related products, the noise level increases. We will need some thought leadership on this. I was delighted to see people I've worked with and included in my community are connected at 1st level LinkedIn with you too, such as Ken Yancy, Michael Thompson, and Mary Henderson. You were wise to bring this into the open instead of limiting to paywall only.