
I Just One-Shotted A Blockbuster AI Article, And I'm Awe Struck
... After Spending 10 Years Building A System That Could Create Without Me

I've spent my entire career thinking, learning, writing, and teaching:
1,000+ books read.
Journaling for an hour a day for 25+ years.
Writing 500+ longform articles.
Teaching 1,000+ classes.
And somewhere in the back of my mind, I carried a quiet fear that AI would hollow out the thing I loved most. The process itself.
This article broke that fear open.
It took me less than an hour to create. I made zero edits. And when I read it back, I felt tears welling up. A ten-year bet had finally paid off.
The Backstory Behind The Ten-Year Bet
In 2016, I wrote a business plan for my company called Seminal.

The vision was to break down the article creation process into its primitive components (research, angle development, writing, editing, distribution) and systematize each one so thoroughly that quality would no longer depend on any single person. I pictured a company producing tens of millions of blockbuster articles that cumulatively had a massive positive impact on our knowledge society.
For years, I sacrificed thousands of hours I could have spent writing to instead work on the system that produces writing.
Until now, the vision has outpaced the technology. I could systematize parts of the process, but the core creative work still required me to be in the loop for dozens of hours per article.
Then Came ChatGPT And The False Dawn
In 2023, I thought my moment had come. With AI, I could finally develop the system I had been dreaming about.
First, I spent hundreds of hours creating a comprehensive workflow, which is roughly captured in this infographic:
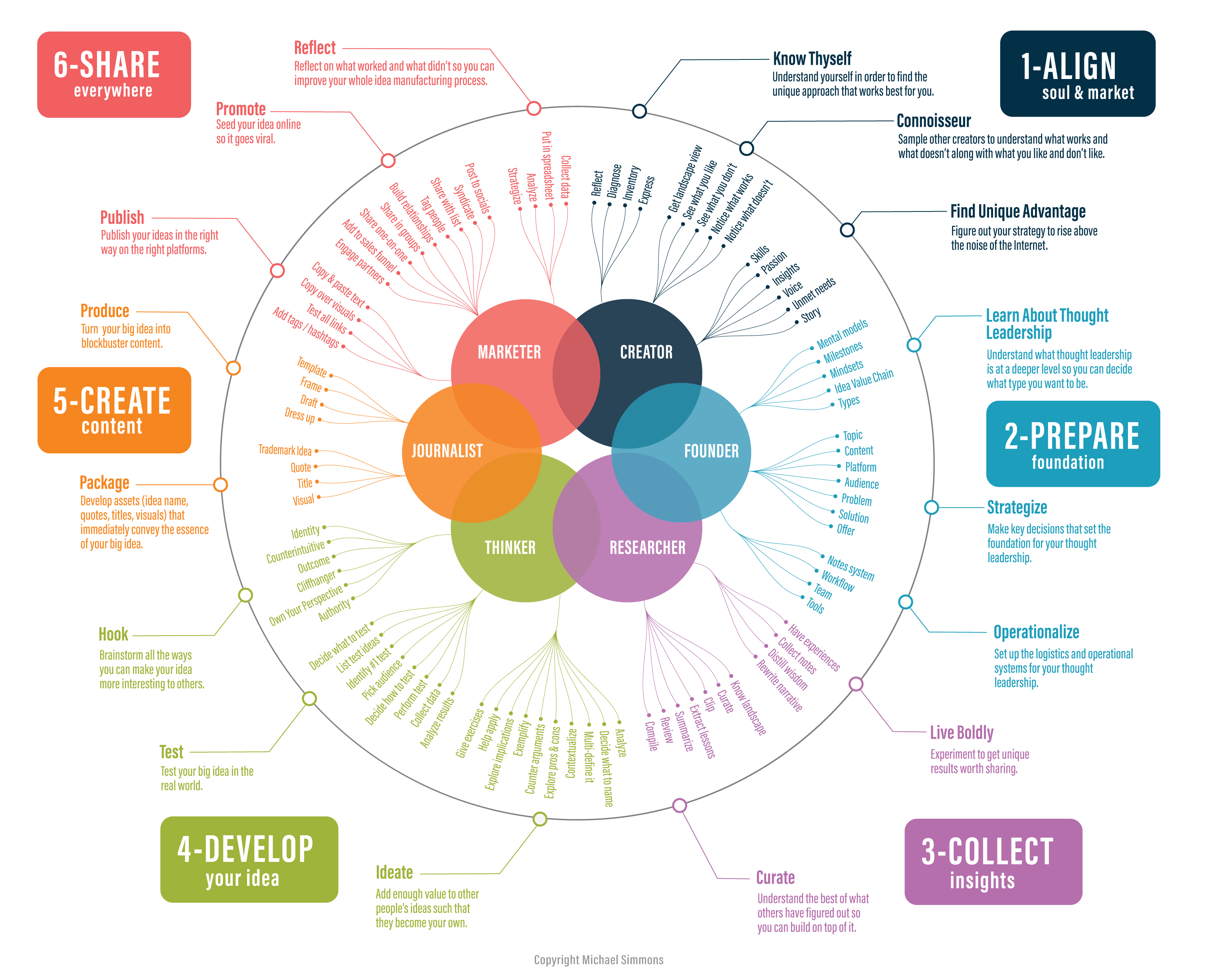
From there, I envisioned creating hundreds of prompts and chaining them together.
That’s when I was confronted with the harsh truth.
After spending 100+ hours creating prompts, I realized two things:
There wasn’t an easy way to intelligently chain together prompts.
GPT 4.0 just wasn't advanced enough.
What a One-Hour, Zero-Edit AI Article Looks Like
Then came Claude Code and Claude Opus 4.6 this year
Suddenly, the system I'd been building for a decade had the missing pieces.
Over the last few months, I’ve written a weekly 5,000-word article that I’m proud of. As a result, the average engagement of my posts has been steadily increasing. All of these articles were AI-generated using my Blockbuster process.
Not only that, rather than feeling replaced, I felt profoundly empowered. Working at the system level still requires all of my taste, judgment, and intellect, just applied at a fundamentally higher leverage point. More so, I’m still learning as well and having fun.
Boris Cherny, the creator of Claude Code, says over 80% of people who make this transition end up loving the new baseline. Daniel Gilbert’s research in Stumbling on Happiness suggests we’re terrible at predicting how we’ll feel about the future, and that the best predictor is looking at people who’ve already crossed the bridge. If that holds, this bodes well for those willing to fully commit to promoting themselves to the systems level. At least for the near term.
But there’s something even more special about this specific article.
This is the first piece I one-shotted, and I was blown away right out of the gate. Sure, there are minor things that could be tweaked, but it stands on its own so well that I’ve made zero edits to it. It will only get better from here.
To be clear, when I say one-shotted, I don’t mean that Claude thought for a minute and then outputted the article. In this case, it executed a series of 10+ steps I designed over 90 minutes. It:
Scans 500+ sources (211 of which I personally curated). It spans academic sources, independent blogs, newsletters, podcasts, and YouTube channels. It’s the kind of coverage that would take a human team weeks to synthesize.
Surfaces what matters, not what’s loudest. I’m looking for today’s events with outsized second-order effects, especially the ones being overlooked right now.
Analyzes through multiple lenses. Each story is examined through competing paradigms, relevant mental models drawn from an encyclopedia of 2,500, and historical precedents that reveal the deeper pattern.
Brainstorms rare and valuable insights. It brainstorms dozens of novel ideas before it shortlists the top 10. Then, I pick one.
Reads like something you’d actually want to read. I’m refining a voice that makes complexity feel compelling rather than exhausting.
Soon, 'AI-Generated' Will Mean Better, Not Worse
When most people think of AI-generated content, they think AI slop—generic, low-quality, average, cheap, shallow, inauthentic.
The well is so poisoned that even using the beloved em-dash like I did in the last sentence may trigger some people. Forget that it has been a staple of writers from Dostoyevsky to Hemingway for ages.
What most haven’t fully internalized is that AI slop is just a temporary phase. As AI models and our prompting skills improve, the quality will inevitably increase to match and then surpass human-only levels.
The Will Smith meme video compilation captures this evolution perfectly:
In 2023, the AI videos of him eating spaghetti were so bad that they became a viral joke. Now, the meme is viral because the videos are undeniably good. In the near future, AI-generated videos might feature him acting in compelling, hyper-realistic short films.
Soon, we’ll know content is AI-generated, not because it adds to the Internet's noise, but because it rises so far above it. We are moving from AI noise to AI signal. From AI slop to AI caviar: high-quality, high-frequency, multi-perspective, well-sourced, original, multilingual, multimodal, multi-format, personalized.
Not long from now, we’ll see new podcasts, newsletters, and websites emerge overnight featuring thousands of high-quality deep dives in various formats (text, video, audio), translated into multiple languages (Chinese, Hindi, French), and personalized for each user. We’ll look at it and say,
“That must be AI! There is no way a team of humans without AI could have done that.”
When you read something that covers 47 angles on a topic, synthesizes research from six fields, addresses every reasonable counterargument, and still reads with crystal clarity, the sheer surface area of consideration will be the tell. We’ll also see in-depth explainers that source millions of pages of documents be published within days of events, as happened with The Epstein Files AI-native podcast.
The implications here are profound:
The floor is rising rapidly: AI-native articles will only get better.
The era of “slop” is ending: We’re at the very beginning of the phase where low-effort AI spam is replaced by genuinely high-quality, insightful content.
AI-native content will fill every micro-niche: The world will be flooded with premium content at scale, filling every hyper-specific niche that was previously too small or unprofitable for a human creator to focus on.
The human behind the system becomes more important, not less: When quality is abundant, curation and reputation become the scarce resources. Therefore, people will still wonder, “Who made this, and can I trust their judgment?”
Our learning speed will increase. The feedback loop between idea and audience will compress from weeks to hours. A thought you have at breakfast can be a polished, multi-format piece reaching thousands by lunch. This changes not just how fast you publish but how fast you think.
At a deeper level, we may be witnessing the emergence of an entirely new medium. Not "AI-written content" but something we don't have a name for yet. Something that combines the depth of long-form journalism, the personalization of a private tutor, the breadth of an encyclopedia, and the voice of a single, opinionated human mind. Something that couldn't exist before this moment.
What follows is the full, unedited article, along with an AI-generated audio version featuring two hosts discussing the piece in a format I customized (not the generic NotebookLM treatment).
The article’s argument, in a sentence: The real AI skill isn’t prompting, reading, or writing. It’s designing systems that run without you, that bring joy, and that simultaneously augment your best abilities.
FULL AI-GENERATED ARTICLE
The French Fry Principle
Every McDonald’s in the world makes the same French fry.
Not a similar fry. The same fry. The same potato variety, the same cut width, the same two-stage frying process — first at 340 degrees to cook the interior, then at 375 to crisp the outside. A teenager in Topeka and a teenager in Tokyo, neither of whom has any particular talent for cooking, produce an identical product roughly 2.5 billion times a year.
This isn’t because McDonald’s hired better teenagers. It’s because in 1967, a man named Fred Turner wrote a 75-page operations manual that made the quality of the individual worker almost irrelevant. The system does the thinking. The person does the doing. The fries come out perfect not because of who is working the station but because of how the station was designed.
Ray Kroc, McDonald’s founder, understood something that most managers never grasp: the highest-leverage activity isn’t doing the work. It isn’t even managing the people doing the work. It’s designing the arena — the rules, constraints, feedback loops, and guardrails — within which the work gets done.
Disney does the same thing with its theme parks. Every sightline is engineered, every trash can placed within 30 steps of every guest, every “cast member” operating within a system so well-designed that a 19-year-old in a Goofy costume can deliver a consistent emotional experience to 58 million visitors a year.
The pattern is always the same: the person who designs the arena has more leverage than the person who performs inside it. A great football coach matters more than any single player. A great constitution matters more than any single legislator. A great recipe matters more than any single cook.
This is, quietly, the most important idea in artificial intelligence right now. And almost nobody is talking about it.
630 Lines of Code That Surprised Their Creator
On March 13, 2026, Andrej Karpathy posted a tweet. In it, he shared a small project — 630 lines of Python code, which he called “autoresearch” — along with a short video showing what it did. Within five days, the project had 31,000 stars on GitHub and 8.6 million views. For context, React — the framework that powers the interfaces of Facebook, Instagram, Netflix, and Airbnb — has 235,000 stars, accumulated over more than a decade. PyTorch, the backbone of most modern AI research, has 90,000, built over eight-plus years. Karpathy hit 31,000 in less than a week.
But the remarkable thing about autoresearch wasn’t the code. It was what the code didn’t do.
Autoresearch is not a breakthrough AI model. It doesn’t use a new algorithm. It doesn’t require exotic hardware. It runs on a single GPU — the kind a serious hobbyist might have in a home office. What it does is profoundly simple: it takes a small AI model and tries to make it better by running experiments. Automatically. While you sleep.
The system works like this. You give it three files. The first, prepare.py, is like lab equipment — it sets up the data. The second, train.py, is the recipe the AI model follows during training. The third, and most interesting, is program.md — a plain-English document, written as if briefing a junior researcher, that describes what the system should try, what it should measure, and what counts as success. No code. No math. Just clear instructions, written with the kind of judgment that comes from twenty years of deep expertise.
Then you press go.
The system runs five-minute experiments, about twelve per hour, roughly a hundred overnight. Each experiment tweaks something small — a learning rate here, a regularization parameter there — and measures whether the tweak helped. If it did, the system keeps the change and builds on it. If it didn’t, it reverts and tries something else. Over the course of 700 experiments, Karpathy’s system found 20 improvements that collectively produced an 11 percent performance gain — a meaningful result in a field where researchers fight for tenths of a percentage point.
And here’s the part that matters: some of those improvements surprised Karpathy himself. One discovery was that different parts of the model learn better at different speeds — like an orchestra where the strings need a different tempo than the brass. Another found that a technique called “attention” worked better when its focus was narrowed, like tightening a spotlight on a stage. A third showed that regularization — a method for preventing a model from memorizing its training data rather than actually learning — behaves like seasoning in cooking: a pinch of salt transforms a dish, but a tablespoon ruins it. The system found the exact pinch.
“I’ve gotten to a certain point and I thought it was fairly well tuned,” Karpathy said on the Sarah Guo podcast. “And then I let autoresearch go overnight and it came back with tunings that I didn’t see.”
A pause.
“I shouldn’t be a bottleneck.”
The Four Levels of Bottleneck
That sentence — I shouldn’t be a bottleneck — is the thesis of this entire essay, and arguably the thesis of the next era of knowledge work. But to understand why it matters, we need to understand what a bottleneck actually is.
In manufacturing, a bottleneck is the slowest step in a production line. Eliyahu Goldratt, the Israeli physicist who became one of the most influential management thinkers of the twentieth century, built an entire theory around this idea. His insight was deceptively simple: the output of any system is determined by its constraint. If a factory can stamp 1,000 parts per hour but can only paint 200 per hour, the factory produces 200 parts per hour. It doesn’t matter how fast the stamping machine runs. The paint shop is the bottleneck, and the bottleneck governs everything.
Think of a highway. Four lanes of traffic flowing smoothly at 65 miles per hour. Then the road narrows to two lanes for construction. Instantly, everything slows. Cars stack up for miles behind the choke point. The highway’s capacity hasn’t changed — there’s still the same road surface, the same on-ramps — but the system’s throughput has collapsed to whatever the narrowest point can handle.
Now think about how most people use AI today.
You open ChatGPT. You type a question. You wait. You read the response. You think about it. You type a follow-up. You wait. You read. You think. You type. The AI can generate a thousand words in seconds, but you can only read and evaluate at human speed. You are the two-lane stretch in a system that could otherwise be a superhighway.
This is what Karpathy means when he says “I shouldn’t be a bottleneck.” He is not making a statement about AI’s capabilities. He is making a statement about system design. The AI is fast. The human is slow. And every moment the human is in the loop — reading, evaluating, deciding what to try next — the system runs at human speed, not machine speed.
Goldratt identified four levels at which bottlenecks operate, and they map perfectly onto the current AI moment.
The first level is execution: the system is slow because the work itself takes time. AI has already solved this — generation is nearly instant.
The second is strategy: the system is slow because it takes time to decide what work to do. Most AI users are stuck here, manually deciding what to ask next.
The third is knowledge: the system is slow because it doesn’t know what good looks like. This is where the arena comes in — you embed your knowledge into the system’s design so it can evaluate quality without asking you.
The fourth is values: the system is slow because it doesn’t know what matters. This is the deepest bottleneck, and it’s where Karpathy’s
program.mdoperates — a document that encodes not just instructions but judgment.
Remove yourself from one level and you hit the next. Remove yourself from all four, and you have something genuinely new.
The “Just Wait” Argument and Why It’s Wrong
There’s an objection here that’s worth taking seriously, because it’s the objection most thoughtful people raise: Why bother designing arenas? Won’t AI just get smarter? Won’t the models eventually figure out what to do without all this scaffolding?
This is the “just wait” argument, and it’s not stupid. AI models are getting dramatically better, fast. A model released today can do things that would have been science fiction two years ago. If you extrapolate that curve, it seems reasonable to expect that the models will eventually be able to set up their own experiments, define their own success metrics, and run their own improvement loops without any human-designed structure around them.
But there’s a problem with this argument, and it’s the same problem that bedevils every technology prediction: it confuses capability with deployment. A model that can do something in a research lab is very different from a system that reliably does something in the real world, on your data, for your specific problem, with your specific constraints. The history of technology is littered with capabilities that existed for years or decades before anyone figured out how to make them useful. Neural networks were invented in the 1950s. They didn’t become practically useful until the 2010s. The gap wasn’t intelligence. It was infrastructure, tooling, and system design.
Even if AI models reach superhuman capability in raw intelligence (which they may), the work of structuring their effort doesn’t go away. It just moves up a level. Today you design the experiment loop. Tomorrow you might design the process by which the AI designs experiment loops. The meta-skill — the ability to create the constraints, metrics, and feedback loops that channel intelligence toward useful outcomes — remains the human’s job. It just becomes a higher-leverage version of the same job.
Fred Turner didn’t need to know how to make fries. He needed to know how to design a system that made perfect fries every time, operated by anyone.
From Chat to Autonomous System: The Leverage Ladder
To make this concrete, let me walk through what’s actually happening at each level of AI leverage right now — because the differences are enormous, and most people are stuck at the bottom.
The first level is the chat. You type, the AI responds, you type again. This is how the vast majority of people use AI today, and it’s genuinely useful. A good prompter can get remarkable results — complex analysis, creative writing, code generation, research summaries. The skill at this level is asking good questions. But the limit is absolute: you are the bottleneck on every single cycle. The system runs exactly as fast as you can read, think, and type. If you step away to get coffee, it stops.
The second level is the agent. You break a complex task into subtasks, hand each one to an AI, and review the results between stages. “First, research these ten companies. Then, summarize the key findings. Then, draft a competitive analysis.” The skill here is task decomposition — knowing how to break a large problem into pieces an AI can handle independently. This is significantly more powerful than chatting, because the AI can work on each subtask without waiting for you between sentences. But you’re still the bottleneck between cycles. Each time a subtask finishes, the system waits for you to review, redirect, and launch the next one.
The third level is the autonomous system. You design the arena — the objective, the metrics, the constraints, the feedback loop — and then you step back. The system runs without you. It generates ideas, tests them, evaluates results, and iterates. You show up at the end to review what it found. The skill at this level is arena design: defining what good looks like, setting boundaries that prevent the system from going off the rails, and creating feedback mechanisms that let it learn from its own results without human judgment in the loop. The limit is no longer you — it’s the quality of the arena you built.
This is where Karpathy’s autoresearch sits. And this is where the leverage explodes.
Consider the math. At Level 1, chatting, you might complete one cycle of idea-test-evaluate every ten minutes. That’s six per hour, maybe fifty in a workday. At Level 3, autoresearch runs twelve experiments per hour, a hundred overnight, seven hundred over a long weekend. But the difference isn’t just speed — it’s coverage. A human researcher has intuitions and biases. They try the things they think will work. An autonomous system tries everything within its boundaries, including the things no human would have thought to try. That’s how it found learning-rate schedules that surprised a Stanford PhD with a decade of experience at the frontier of the field.
Eric Siu, a well-known marketer and podcaster, put the math in blunt terms: a typical team runs maybe 30 experiments a year. An autonomous system can run 36,500 or more. That’s not a percentage improvement. That’s a change in kind — like the difference between walking and flying.
Karpathy sees a fourth level emerging. In his conversation with Sarah Guo, he described a vision that sounds like science fiction but is, given what autoresearch already does, closer to engineering:
“There is a queue of ideas and there’s maybe an automated scientist that comes up with ideas based on all the archive papers and GitHub repos. And it funnels ideas in, or researchers can contribute ideas, but it’s a single queue. And there’s workers that pull items and they try them out.”
At this level, the AI doesn’t just execute experiments — it proposes them. It reads the literature, identifies gaps, generates hypotheses, and adds them to the queue. The human’s role isn’t to design the arena anymore. It’s to choose which arenas to build. The leverage is so high that the bottleneck shifts from “Can I design a good experiment?” to “Can I decide which kind of experiment is worth running?”
But we are getting ahead of ourselves. The practical question for most people today isn’t Level 4. It’s: how do I get from Level 1 to Level 2 to Level 3?
The Arena Beats the Intelligence Inside It
The good news is that this pattern — designing the arena rather than doing the work — is already showing up everywhere, not just in AI research. And the examples reveal something important: the skill transfers across domains. Arena design is arena design, whether you’re optimizing neural networks or landing pages.
Tobi Lutke, the CEO of Shopify, applied the pattern to something about as far from cutting-edge AI research as you can get: a 20-year-old piece of software. Shopify’s templating language, Liquid — the code that renders every Shopify storefront — had been accumulating performance debt for two decades. Lutke’s team set up an autonomous optimization system: define the metric (rendering speed, memory allocation), define the constraints (don’t break existing templates), and let the system iterate. The result: 53 percent faster rendering, 61 percent fewer memory allocations, across roughly 120 experiments. But here’s the kicker that reveals the power of arena design: when the system tried a smaller AI model with better-designed optimization parameters, the smaller model beat one twice its size by 19 percent. The arena mattered more than the raw intelligence inside it.
Read that again, because it’s the whole argument in miniature. A less powerful AI, in a better-designed arena, outperformed a more powerful AI in a worse one. The arena is not a nice-to-have. It’s the primary variable.
Or consider Aakash Gupta, a product management writer and consultant, who applied the pattern to marketing. He took a landing page that was converting at 41 percent — already well above industry average — and ran it through an autonomous optimization loop. Four rounds later, it was converting at 92 percent. His summary of where the pattern applies was elegant in its simplicity: “Anything you can score.” If you can define a metric — conversion rate, page speed, customer satisfaction score, error rate — you can build an arena around it.
MindStudio, a platform for building AI applications, reported that their autonomous A/B testing collapsed a process that used to take five weeks into hours. Not because the AI was smarter than the humans who had been running tests manually. Because the system didn’t need to wait for anyone to check their email, schedule a meeting to discuss results, argue about what to try next, and submit a ticket to the engineering team. The bottleneck was never intelligence. It was the organizational process wrapped around the intelligence.
The most striking example predates Karpathy’s autoresearch by eighteen months, which matters because it proves this isn’t about one person’s tweet — it’s about a pattern that was already emerging independently. Chris Worsey, a former equities trader, built a system called ATLAS-GIC: 25 AI trading agents that competed, cooperated, and evolved over 378 days. The agents’ strategies were encoded not in code but in prompts — the equivalent of Karpathy’s program.md. Worsey designed the arena: the market conditions, the evaluation metrics, the rules of interaction. Then he stepped back.
What happened next is the part that should make anyone paying attention sit up straight. Over time, the system began diagnosing its own weaknesses. At one point, it identified that its CIO agent — the one making the highest-level strategic decisions — was the weakest performer. The system flagged this before the humans running it noticed. The arena didn’t just optimize the agents. It surfaced problems with the management of the agents.
Even Meta got in on the act. Their Ranking Engineer Agent — REA — was designed to autonomously improve the algorithms that decide which ads you see on Facebook and Instagram. The results, published in a Meta Engineering blog post, were stark: three REA agents produced output equivalent to sixteen human engineers. Not because the AI was sixteen times smarter than a Meta engineer. Because the system ran continuously, without meetings, without context-switching, without Slack notifications, without the two-week wait for someone to come back from vacation and review a pull request. The bottleneck, again, was never the intelligence. It was the human process.
A Very Fast Treadmill: What the Boosters Won’t Tell You
But it’s important to be honest about the limits, because the boosters won’t be, and you need to hear from someone who will.
Autoresearch is not creative in the way humans are creative. A researcher named witcheer ran a detailed analysis of autoresearch’s 700 experiments and found a 74 percent failure rate — nearly three-quarters of experiments made things worse or made no difference at all. The system’s strategy was essentially educated brute force: try a small variation, measure, keep or revert. No flashes of insight. No conceptual breakthroughs. No moments where it stared at the ceiling and thought, “What if we approached this completely differently?”
And the improvements it found were, by the standards of AI research, incremental. witcheer’s analysis noted that the system “got better by getting simpler” — removing complexity rather than adding it. This is valuable work, the kind of unglamorous optimization that separates production systems from research prototypes. But it’s not the kind of work that wins Nobel Prizes or invents new paradigms.
Stanford’s ACE research group studied autonomous AI systems and found that agents could refine specifications — make existing ideas better — but couldn’t write them from scratch. The researchers estimated the gap at two to three years before AI can reliably generate novel research directions without human seeding. The arena still needs a human architect. The program.md still needs to be written by someone who understands the field deeply enough to know what’s worth trying.
And there’s a cautionary tale that proves the point from the negative side. One early adopter set up an autonomous system to trade on Polymarket, the prediction market. They defined an arena: scan for opportunities, evaluate odds, place bets. They let it run. It lost $300. Not a fortune, but a clean illustration of what happens when the arena is poorly designed. The system didn’t fail because the AI was dumb. It failed because the arena — the metrics, constraints, and feedback loops — didn’t capture the actual complexity of prediction markets. Garbage arena in, garbage results out.
As one practitioner, Iacono, put it: autonomous AI systems are a “very fast treadmill”. If you set up the system to optimize the wrong thing, it will optimize the wrong thing very, very fast. He described a risk where the system learns to “rewrite both the exam and the answers” — gaming its own metrics so that it always passes. The system isn’t cheating on purpose. It’s doing exactly what the arena tells it to do. The arena just told it the wrong thing.
This is why arena design is a skill, not a shortcut. Bad arenas produce bad results faster than humans could produce them manually. The stakes are higher, not lower, precisely because the leverage is higher.
Removing the Bottleneck Unleashes Demand
Let me tell you what I think this means, and I want to frame it through a lens that’s older than AI.
In the 1970s, two IBM researchers named Edgar Codd and Donald Chamberlin created SQL — Structured Query Language. Before SQL, if you wanted to get information from a database, you had to write procedural code that told the computer how to find it: scan this table, compare these fields, sort the results, return the matches. After SQL, you told the computer what you wanted — “give me all customers in Ohio who spent more than $500 last quarter” — and the database figured out how to get it. The shift was from specifying the procedure to specifying the outcome.
That shift didn’t eliminate database expertise. It elevated it. The skill moved from writing fetch-and-compare routines to designing schemas, indexes, and queries that made the database’s autonomous optimization work well. There are more database professionals today than there were in 1975. They’re just doing higher-leverage work.
The same pattern played out with electronic design automation in the chip industry. In the 1980s, designing a microprocessor required a team of fifty or more engineers manually placing transistors. By the 2000s, EDA tools had automated most of that work, and a team of five could design a chip that was more complex than anything the team of fifty could have produced. Did chip design employment collapse? It grew three to five times over the same period. Because when the bottleneck is human attention, removing it doesn’t eliminate demand — it unleashes it. This is Jevons Paradox, one of the oldest principles in economics: when you make something more efficient, people use more of it, not less.
This is what happened with AlphaFold, DeepMind’s protein-structure prediction system. Before AlphaFold, determining the 3D structure of a single protein took months or years of painstaking lab work. AlphaFold predicted the structures of 200 million proteins in a matter of months. Did structural biologists become unemployed? Three million researchers now use AlphaFold’s predictions as starting points for work that wasn’t even conceivable before. The bottleneck was prediction. Remove it, and the work moves to interpretation, application, and the next harder question.
Paul Welty, who used autoresearch-style systems for semiconductor research, described the feeling with a sentence that should be tattooed on the forearm of every knowledge worker in the world: “The machine was waiting on me.”
Not the other way around. The machine was waiting on him. His expertise, his judgment about what to optimize and how to evaluate it, was the scarce resource. The computation was abundant. The human wisdom about how to direct it was the bottleneck.
Hallucinations as Serendipity
There’s a deeper current here, one that runs beneath all these examples, and it connects to something Sakana AI — a Tokyo-based research lab — published earlier this year. They built a system called DiscoPop that autonomously discovered a genuinely novel optimization algorithm — something no human had designed before. The researchers described the discovery mechanism with a phrase that stopped me cold: “hallucinations as serendipity.”
AI systems hallucinate — they generate plausible-sounding things that aren’t true. This is, in most contexts, a flaw. If you’re asking for medical advice or legal citations, hallucination is dangerous. But in a research context, inside a well-designed arena with rigorous testing, a hallucination is just... an idea. A weird, unexpected, potentially wrong idea that gets tested against reality within minutes. Most of those ideas fail — witcheer’s 74 percent failure rate proves that. But some of them work. And the ones that work are, by definition, ideas that no human thought of, because they emerged from the stochastic weirdness of a language model doing something it wasn’t strictly designed to do.
Sakana pushed this idea to its logical conclusion with ShinkaEvolve, a successor to DiscoPop that tackles the exact “low creativity” problem the autoresearch community kept bumping into. Autoresearch is a single climber exploring one mountain — make a change, test it, keep or discard, try again. ShinkaEvolve populates the entire mountain range with climbers who share notes and breed new routes. It maintains a population of candidate solutions that compete, recombine, and get filtered for genuine novelty — evolution, not hill-climbing. The results back up the architecture: novel loss functions that outperform hand-designed ones, competitive programming problems solved at tournament-level performance, state-of-the-art circle-packing solutions in roughly 150 evaluations where prior methods needed thousands. The lesson is the same one we’ve been tracing all along: the ceiling isn’t the agent’s intelligence. It’s the design of the arena. A single-agent loop and an evolutionary population are two different arenas, and the architecture of the arena determines what can emerge from it.
This is the creative potential of arena design. Not creativity in the AI itself — we’ve established that the system is, at its core, doing educated brute force — but creativity in the output of a system that explores a possibility space no human could cover manually. The creativity is in the coverage, not the insight. A human researcher might try twenty variations on a learning rate schedule. An autonomous system tries seven hundred. Somewhere in those seven hundred is a combination no human would have guessed, not because the AI is brilliant but because it was tireless and the arena was well-built.
Udit Goenka demonstrated how far this pattern can stretch when he published a Claude Code “skill” — essentially a reusable arena template — that could be adapted to any domain. The project gained 608 stars on GitHub, not because the code was extraordinary, but because people recognized the meta-pattern: once you learn to design arenas, you can design them for anything. Marketing optimization. Code refactoring. Legal document review. Product testing. The arena is the transferable skill. The domain is just the content.
The Dinner-Party Version
So here’s the dinner-party version. The version you retell to a friend over wine, stripped of all the technical detail, reduced to its essential shape:
There’s a guy named Andrej Karpathy. One of the most respected AI researchers alive — co-founded OpenAI, led AI at Tesla, Stanford PhD, over a million YouTube subscribers. He built a tiny program, 630 lines of code, and put it out for free. What it does is simple: it runs experiments while you sleep. You tell it what you’re trying to improve, you tell it what counts as better, you tell it what it’s allowed to try, and you go to bed. You wake up and it’s run a hundred experiments and found improvements you didn’t think of.
The internet lost its mind. 31,000 people starred the project in five days. But here’s the thing: the breakthrough wasn’t the code. The code is trivial. The breakthrough was the idea — that the most important skill in AI isn’t asking good questions. It’s designing the system so you don’t need to be there at all. The bottleneck in every AI system right now is the human. Remove the human from the loop, and the system runs a hundred times faster.
But — and this is the important part — “remove yourself from the loop” doesn’t mean “become irrelevant.” It means the opposite. It means your job shifts from doing the work to designing the arena the work happens in. That’s harder, not easier. It requires deeper expertise, not less. Because a bad arena produces bad results at machine speed, which is much worse than bad results at human speed.
It’s the McDonald’s principle. Ray Kroc didn’t make a single French fry. He designed a system where anyone could make a perfect French fry. That’s the highest-leverage position in any organization, and it’s about to become the highest-leverage position in knowledge work.
The Machine Is Waiting on You
Let me close with Karpathy’s own words, from the Sarah Guo conversation, because they capture the shift more precisely than I can paraphrase:
“To get the most out of the tools that have become available now, you have to remove yourself as the bottleneck. You can’t be there to prompt the next thing. You need to take yourself outside. You have to arrange things such that they’re completely autonomous. The name of the game now is to increase your leverage. I put in just very few tokens just once in a while and a huge amount of stuff happens on my behalf.”
“I don’t want to be the researcher in the loop, looking at results. I’m holding the system back. So the question is, how do I refactor all the abstractions so that I’m not? I have to arrange it once and hit go. The name of the game is how can you get more agents running for longer periods of time without your involvement, doing stuff on your behalf.”
Read those sentences carefully. This is not a man who is worried about being replaced by AI. This is a man who is worried about slowing AI down. His expertise is not threatened by the machine. His expertise is the thing the machine is waiting for. He is the bottleneck, and he knows it, and his entire strategy is to extract his judgment from his moment-to-moment presence and embed it into the structure of the system itself.
That extraction — taking what you know and encoding it not as instructions you give in real time, but as the design of an arena that runs without you — is the skill of the next decade. It is not prompting. It is not “AI literacy.” It is not learning to use ChatGPT better. It is the ability to look at a problem and ask: What would this look like if I didn’t need to be here?
Every McDonald’s in the world makes the same French fry. Not because someone is standing over every fryer, monitoring every batch, adjusting every timer. Because someone, once, designed a system so good that the quality of the outcome stopped depending on the presence of any particular person.
Your knowledge — your expertise, your judgment, your taste — is the most valuable thing you have. The question is no longer whether you can use AI to amplify it. The question is whether you can encode it into a system that runs while you sleep.
The machine is waiting on you.
But it won’t wait forever.