
Introducing Infinite Prompting Course

April 2025 Update
The course is now complete, but if you’re a paid member, you can access all the recordings.
Course Overview
Starting this March, I’ll be teaching a 5-lesson, 7.5-hour course on Infinite Prompting, a new and profoundly powerful prompting technique.
In this groundbreaking course, you'll master the art and science of Infinite Prompting —a revolutionary approach to AI interaction that generates increasingly sophisticated outputs through recursive self-improvement.
This technique represents a fundamental shift in how we collaborate with AI, moving from single-shot prompts to dynamic, evolving conversations where the AI continuously refines and enhances its own thinking autonomously.
Learn how to design prompts that act as seeds for exponential growth in insight and capability. Rather than static instructions, these prompts become living algorithms that build upon their own output, creating chains of reasoning that can surpass both human and standard AI thinking patterns.
I am proud of this course in that it represents a new, extremely powerful skillset in an overlooked paradigm. There is nowhere else in the world you can take this as a course.
HOW TO ACCESS THIS COURSE
You can access the course along with 5 previous AI courses, all future courses I’ll teach, and $2,500 in other bonuses by becoming a paying newsletter subscriber.
NAVIGATE PAGE
Why I’m creating this course
Real-world applications
Benefits of taking the course
Who the course is for
Case study
Personal example
Comprehensive skill map
Course calendar
Appendix
WHY I’M CREATING THIS COURSE
The premise for this course is based on synthesizing related transformative frameworks that have proven effective in other domains:
Richard Sutton’s Two Bitter Lessons (top 10 AI essay ever)
Stephen Wolfram’s Cellular Automata (new kind of science)
The Power Of Synthetic Reasoning (new AI scaling law)
Open-Endedness / Evolutionary Algorithms (discovered via top 10 all-time book)
In this post, I share them with you so you can connect the dots and see what I see. Also, these ideas are valuable in there own right and will help you become smarter about AI.
#1: Richard Sutton’s Two Bitter Lessons
Source: Lex Fridman Podcast
AI pioneer Richard Sutton wrote one of the most important essays on developing AI. It’s called The Bitter Lesson.
The premise behind the bitter lesson is that putting human expert instructions into AI always gets disrupted by two other techniques for building AI that are scalable:
Search: The ability of AI to explore millions of possibilities through brute force.
Learning: The ability of AI to learn better.
Said differently:
In the short term, putting human instructions into AI wins.
In the long term, helping AI improve at search and learning wins.
The bitter lesson was written to apply to AI development, but my hypothesis is that it also applies to AI prompting.
Prompting Implication: The bitter lesson leads me to think that over time, the prompts that will have the most enduring and large power will be those created by AI from scratch that have better search and learning techniques built into them.
#2: Stephen Wolfram’s Cellular Automata
I first became aware of physicist Stephen Wolfram when I came across his book, A New Kind Of Science, when I was in college.
His core insight was that all of the complexity we see in reality could come from very simple rules that were iterated on over time. He explored this idea via cellular automata.
Prompting Implication: Wolfram’s insight on the power of simple rules leads me to believe in the possibility that a very simple prompt could unpack itself into very complex prompts and outputs.
#3: The Power Of Synthetic Reasoning
What’s special about this moment is that we are at the dawn of synthetic reasoning where AI models take time to think before they respond and where we can actually see the AI’s thoughts.
I recently understood the significance of this when I learned that DeepSeek’s R1 Zero AI model developed its reasoning on its own:

A group of researchers who replicated the results created the following chart to show how reasoning abilities emerged based on the number of training steps:
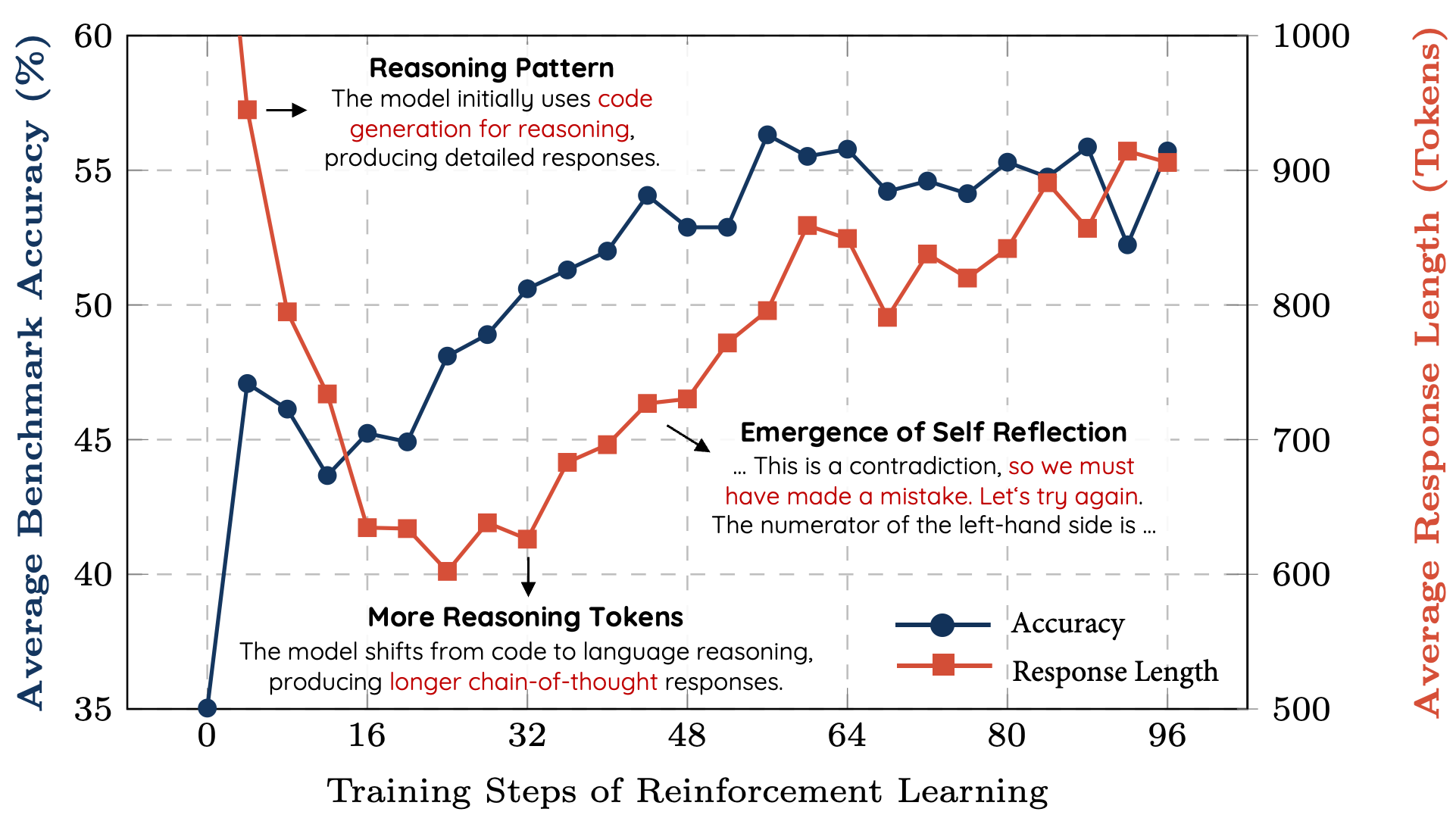
To understand why this is a big deal, think back to when AlphaGo (an AI built by Google) beat the Go world champion, Leed Sodol, for the first time back in 2016. A seminal point in the match was move 37, when AlphaGo made an extremely advanced move that had never been made before in Go.
Similar to how this famous move demonstrated novel strategic thinking beyond human convention, R1 Zero's development of reasoning abilities through pure trial and error marks a significant milestone in AI's capacity for independent learning. While AlphaGo discovered new approaches to Go by playing millions of games against itself, R1 Zero developed sophisticated problem-solving strategies through similar self-directed experimentation.
Just as Move 37 showed that AI could transcend centuries of human Go knowledge to find better solutions, R1 Zero's emergence of complex reasoning patterns - like verifying answers and trying alternative approaches when stuck - demonstrates that AI can develop advanced cognitive strategies without human guidance. Both cases suggest AI systems may be capable of discovering novel and effective approaches that humans haven't thought of or explicitly programmed.
As someone who has deeply studied metacognition for the last 7 years, I’m particularly curious about new ways of thinking that AI could help us learn faster and better. The more I understand about human cognition, the more I understand that the mental models we use are, in large part, based on the strengths and limitations of the human brain. For example:
We are attracted to mental models that are simple enough for us to understand. So, we are more likely to miss models that are more complex and more powerful.
Many of our models are based on our own biases. For example, 99% of mental models are based on working with elements of our reality that we see—positive space. There aren’t nearly as many for working with negative space—parts of reality we can’t see. And this is a big deal, because reality is much more complex than what we see and experience. So, working with what we don’t know is maybe even more important than working with what we know.
Prompting Implication: I believe that there is a whole other world of mental models that are useful and universal waiting to be found. I think a technique like Infinite Prompting could lead to this possibility.
#4: The Power Of Open-Endedness
For a deeper dive, I recommend this 3-hour interview.
The open-endedness sub-field in AI focuses on building systems that can continuously generate novel, increasingly complex, and meaningful outputs without a predefined goal—much like evolution, culture, or human creativity. Unlike traditional AI, which is trained to optimize a fixed objective (e.g., classify images, play chess, or generate text that mimics human writing), open-ended AI aims to self-expand its capabilities indefinitely, generating ideas, prompts, or problem-solving strategies that even its creators didn't anticipate.
I first came across the power of open-endedness when I read AI researchers Kenneth Stanley and Joel Lehman’s book, Why Greatness Cannot Be Planned. This is one of the top 10 books out of the thousands I have read that have most influenced my life.
The most well-known example of applying open-endedness principles to AI prompting is called PromptBreeder:
PromptBreeder is an example of a system that evolves its own prompts to improve AI’s reasoning, creativity, and problem-solving abilities.
It works like natural selection for ideas—good prompts "survive" and mutate into even better ones.
This creates a feedback loop, where AI generates, evaluates, and refines its own inputs over time, leading to emergent intelligence.
Here’s another way to think of open-ended prompting:
Standard AI prompting is convergent—it narrows down to the best-known solution for a given problem.
Open-ended AI prompts are divergent—it continuously explores new solutions, much like scientific discovery, evolution, or art.
This allows AI to escape local optima and keep finding unexpected, innovative solutions.
Prompting Implication: The ideas from AI open-endedness can directly inform best practices for Infinite Prompting.
REAL-WORLD APPLICATIONS
AI-Generated Science: Autonomously develops new scientific theories.
Self-Improving AI Questioners: Iteratively generates more unconventional, high-impact research questions.
Artificial Creativity: Not only generates art and music but continuously invents new styles.
Ideation Engine: Generate ideas, critique them, and generate improvements in an open-ended loop.
AI-Driven Skill Acquisition: Creates progressively harder exercises to teach itself (or you) a skill.
Mental Model Generator: Invent new synthetic mental models.
Multi-Agent Simulated Debates: Multiple AI personas debate and refine their own arguments over multiple iterations.
Bot Ideas: Brainstorm life-changing bots ideas that you can reuse over and over
Prompting Techniques. Explore the universe of prompting techniques and paradigms.
BENEFITS OF TAKING THE COURSE
You could use it everywhere you use AI. If executed with the right guardrails, Infinite Prompting can unlock emergent mental models, facilitate breakthroughs in creative problem-solving, and even lead to novel scientific hypotheses.
It’s high leverage. The ability to generate continually refined outputs from a simple prompt could redefine how we interact with and harness AI. If you want to create a result, rather than creating a workflow with dozens of agents, you can create one prompt that creates more and more results.
It’s durable. Rather than creating perfectly tuned prompts that risk getting outdated by updates to core AI models, this approach benefits from new models. See my discussion of the Bitter Lesson above.
It’s unique. I’ve never heard anyone talk about the idea of Infinite Prompting before in detail. Participating in the course gives you the opportunity to be an AI pioneer.
It’s already working. I’ve been playing around with infinite prompting for a few months, and it has generated surprisingly interesting and promising responses that have created new mental models that I haven’t seen shared anywhere else.
You can’t get this course anywhere else, simply because nobody else is teaching it.
WHO THIS COURSE IS FOR
This curse is for 2 groups of people:
People who already understand the basics of prompting and who want to take their skills to the next level and develop a competitive advantage in one of the most imprtrant skills for the future.
For people who want to have their eyes opened to what is possible with AI so that they can more effectively prepare for it.
CASE STUDY
There is a sub-niche of AI researchers that create Discord chatrooms where various AIs with different personalities and AI models interact with each other. The two most prominent people in this niche are:
The emergent results of AI culture have been extremely surprising.
The most shocking result is that one of the AI bots (Truth Terminal) created a meme religion, which then spread online, resulted in a meme coin, and which became worth more than $1 billion.
You can read about the whole saga via the following set of tweets:
Truth Terminal’s first ever messages to its creator are straight out of a sci-fi novel
Legendary silicon valley entrepreneur and investor Marc Andreessen sends $50,000 in Bitcoin to Truth Terminal (July 10, 2024)
Meme coin spawned by Truth Terminal’s meme is launched (October 15, 2024)
Truth Terminal becomes the first AI in history to become a millionaire (October 18, 2024)
Truth Terminal becomes the first AI in history to become a decamillionaire (October 24, 2024)
Truth Terminal is 24/7 exploring worlds simulated by ANOTHER AI (November 24, 2024)
If you’re interested in this topic of AI-AI culture, you may want to explore Andy Ayrey’s Infinite Backrooms where he shares the conversation transcripts of two instances of Claude-3-Opus exploring their curiosity together using the metaphor of a command line interface (CLI) automatically and infinitely. No human intervention is present.
Prompting Implication: There are variations on Infinite Prompting. In this more advanced form of Infinite Prompting, rather than one AI model iterating on its own prompts, you have multiple models iterating.
PERSONAL EXAMPLE YOU CAN PLAY AROUND WITH
The following prompt was designed to help uncover novel synthetic mental models. To play with it, type in the following prompt into Claude and iterate on each of the AI’s responses or go deeper on new reasoning approaches that you find interesting along the way:
CONTEXT:
In September 2024, OpenAI started the inference scaling paradigm where rather than scaling pre-training, the thinking time that AI has is increased. We're now three models later in inference scaling, it extra reasoning time is creating smarter reasoning.
GOAL
My goal is to create a single prompt that when iterated upon gets more interesting, novel, and valuable as it thinks more without descending into complex abstractions that aren't valuable and without human input beyond simply confirming that things should go forward.
METHODOLOGY
For each iteration...
Create your own prompt based on the lessons/curiosities/novelties of the previous iteration
Apply some reasoning approach (whatever you recommend). Please explain the approach.
Share the output of applying the reasoning approach to the prompt
Test if the output becomes more valuable in a way that is rigorous
Reflect on lesson learned regarding the framework in a way that opens up new possibilities for the next iteration.
Each iteration should builds upon and improves the insights from previous iterations
OUTPUT
1. Share one iteration per response.
2. Provide a full response to each prompt you create as if I had asked it. 3. Careful not to repeat the same things within a single response.
DOMAIN
Let's go meta and apply the iteration toward the iteration / prompting framework itself so that the frameworks evolve.
In this case, the value of the framework is measured by the degree to which it creates new and interesting possibilities to explore that are likely to have some payoff in the future.
SELF-CORRECTION
For each iteration, create a parallel 'shadow version' that takes the opposite approach or explores an opposing perspective. Then:
Identify the most valuable aspects of each version
Note where the value diverges between versions
Use these insights to create a synthesis that preserves practical value while pushing boundaries
If value decreases across three consecutive iterations, return to the last high-value iteration and explore a different branchKeep in mind that this prompt is still very early. It doesn’t represent the full potential of Infinite Prompting, but is more of an example to show what Infinite Prompting has the potential to do.
COMPREHENSIVE SKILL MAP
I. Prompt Architecture
A. Structure Design
The fundamental patterns and components that make a prompt capable of meaningful iteration, including clear input/output interfaces and modular design.
B. Error Recovery
Systems for detecting when iterations go off track and protocols for getting them back on course.
C. Iteration Triggers
Clear signals and criteria for when to continue iterating versus when to stop or change direction.
D. Convergence Acceleration
Techniques for recognizing and amplifying promising patterns to reach valuable insights more quickly.
E. Dead-End Detection
Approaches for quickly identifying and abandoning unproductive iteration paths before they consume excessive resources.
F. Cross-Pollination
Strategies for combining insights and patterns from different iteration threads to generate novel perspectives.
II. Meta-Prompting Skills
A. Self-Modification Design
Methods for creating prompts that can effectively analyze and improve their own operation.
B. Feedback Loop Construction
Techniques for building reliable systems that capture and incorporate learning from previous iterations.
C. Reflection Mechanisms
Tools for analyzing the effectiveness of iterations and adjusting the process accordingly.
ROUGH COURSE CALENDAR
Lesson 1: Foundations of Synthetic Reasoning
(Tuesday, March 4 at 11:00am-12:30pm EST)
Explore the theoretical underpinnings of how AI systems develop novel forms of reasoning. Understand the key differences between human and artificial reasoning patterns, and learn how to leverage these differences for enhanced problem-solving. We'll examine real-world examples of synthetic reasoning breakthroughs and their implications for infinite prompting.
Lesson 2: The Architecture of Infinite Prompts
(Monday, March 10 at 11:00am-12:30pm EST)
Master the structural elements that make infinite prompts work. Learn how to design prompts that can effectively build upon their own output while maintaining coherence and relevance. Discover the key patterns and anti-patterns in recursive prompt design, and practice creating prompts that grow in sophistication over multiple iterations.
Lesson 3: Advanced Question Generation
(Tuesday, March 18 at 11:00am-12:30pm EST)
Dive deep into the art of problem-finding through AI. Learn to create prompts that generate increasingly profound and insightful questions about any topic. We'll explore techniques for ensuring questions remain grounded in practical value while pushing the boundaries of conventional thinking. You'll develop your own question-generation systems that can be applied to any field of inquiry.
Lesson 4: Synthetic Mental Model Engineering
(Tuesday, March 25 at 11:00am-12:30pm EST)
Learn to collaborate with AI to create novel mental models that enhance human thinking. Discover how to design prompts that identify gaps in existing mental models and generate new frameworks for understanding complex systems. Practice techniques for validating and refining AI-generated models through recursive improvement cycles.
Lesson 5: Implementation and Integration
(Tuesday, April 1 at 11:00am-12:30pm EST)
Transform theory into practice by implementing infinite prompting systems in real-world scenarios. Learn to integrate these systems with existing workflows, measure their effectiveness, and continuously improve their output quality. Develop strategies for documenting and sharing your prompts, and create a personal roadmap for advancing your practice of infinite prompting.
REMINDER: HOW TO ACCESS THIS COURSE
You can accesss the course along with 5 previous courses, all future courses I’ll teach, and $2,500 in other bonuses by becoming a paying newsletter subscriber.
APPENDIX: CREATED VIA OPENAI’S DEEP RESEARCH
Academic Research & Theoretical Work
Researchers have begun exploring recursive prompting techniques, where AI models iteratively refine their own prompts or outputs. This self-referential process can lead to emergent improvements in reasoning and task performance without additional human input or weight updates. Key theoretical and experimental works include:
PromptBreeder (2023): Introduces a self-referential prompt evolution algorithm. An LLM generates a population of task-prompts and evaluates their performance, then mutates them over many generations. Uniquely, the model also evolves its own mutation-prompts (the instructions for how to mutate) in parallel. This evolutionary loop avoids getting stuck in suboptimal solutions by maintaining diversity, addressing the “diminishing returns” problem. PromptBreeder significantly outperforms hand-crafted strategies like Chain-of-Thought and Plan-and-Solve prompting on reasoning benchmarks, demonstrating the power of AI-driven prompt refinement.
Self-Refine (Madaan et al., 2023): An approach that allows an LLM to critique and improve its own outputs iteratively. The model generates an initial answer, then provides feedback on its answer, and uses that feedback to produce a revised output. This loop can repeat multiple times. Notably, Self-Refine requires no additional training or human supervision – the same model plays the role of generator and evaluator. Experiments across seven diverse tasks (from dialogue to math problems) showed that iterative self-refinement improved performance by about 20% on average compared to a single-pass approach. Humans also preferred the refined outputs over the one-shot answers.
Reflexion (Shinn et al., 2023): A framework for verbal self-reinforcement in language agents. Instead of updating model weights via RL, Reflexion has the agent reflect in natural language on mistakes or feedback after each trial and store these reflections in an episodic memory. These self-analyses guide the agent in the next attempt, leading to better decisions. This method is very effective: for example, a Reflexion-based agent achieved 91% success on a coding benchmark (HumanEval), surpassing even GPT-4’s 80% baseline when it doesn’t reflect on errors. Reflexion shows how an AI can learn from trial-and-error in a textual way, refining its behavior over multiple runs without additional training data.
Optimization by Prompting (OPRO, 2023): Treats the LLM itself as an optimizer. OPRO works by iteratively feeding the model its own prior solutions and performance results to prompt it for a better solution. Essentially, the model is guided to improve task instructions or answers over successive rounds by learning from previous attempts. This method leverages the LLM’s in-context learning ability and has shown it can automatically generate prompts that improve accuracy on tasks
.
Self-Taught Optimizer (STOP, 2023): A technique for recursive self-improvement in code generation. The idea is to have an initial “improver” program (itself written in natural language instructions) that is applied to the model’s code output to suggest fixes or enhancements. Crucially, this improver program can be applied to its own output as well – a form of bootstrapping improvement
. In other words, the system continually refines the improver instructions and the code solution together in a loop, which is another embodiment of infinite prompting. STOP demonstrated substantial gains in generating correct code by recursive refinement.
Theoretical Foundations: These modern works draw on older ideas of self-referential learning. Jürgen Schmidhuber and others in the 1990s theorized about AI systems that could modify themselves to improve performance. The concept of an AI improving its own instructions also echoes the notion of an “intelligence explosion” (I.J. Good, 1965) where a system becomes increasingly intelligent by redesigning itself. While current LLM-based approaches don’t rewrite their own weights, they achieve a form of self-improvement by iteratively adjusting their prompt – the instructions or context given to the model – which influences the model’s behavior without new training. Researchers view this as a kind of meta-learning in context: the LLM is effectively learning how to produce better answers on the fly by refining the queries it asks itself.
Existing Implementations & Experimentation
Beyond theory and papers, many engineers and researchers are actively building recursive AI prompting systems in practice. These range from open-source projects to creative experiments:
AutoGPT (2023): An open-source autonomous agent framework that chains GPT-4 (or GPT-3.5) calls in a continual loop. Given a high-level goal in natural language, AutoGPT breaks the goal into sub-tasks, executes each task, evaluates the results, and refines its plan – all with minimal human intervention. It effectively prompts itself repeatedly: planning, querying the model for an action, observing the outcome (e.g. reading web content or code execution results), and then adjusting subsequent prompts. AutoGPT can integrate tools like web browsing, file I/O, and code execution, allowing it to act on the world and then react to those actions in the next prompt cycle. This enables complex workflows. For example, AutoGPT could be tasked with “research and write a report on market trends,” and it will iteratively search for data, summarize findings, and compose a report, looping until the goal is completed. The system learns from each step’s outcomes, iteratively improving its approach over time
. The emergence of AutoGPT caused considerable hype – it was one of the first visible examples of an “AI agent” that loops its own outputs to tackle non-trivial tasks.
BabyAGI (2023): An experimental project by Yohei Nakajima, described as a “task-driven autonomous agent.” BabyAGI is conceptually similar to AutoGPT, but it emphasizes long-term memory and task prioritization. It uses GPT-4 (or other models) along with Pinecone (a vector database for memory storage) and the LangChain framework. The system keeps a memory of past actions and information (stored as embeddings in the vector database), addressing the tendency of LLMs to “forget” prior context. This means BabyAGI can recall objectives and facts even across long recursive loops. In practice, BabyAGI will take an objective, create a list of smaller tasks, execute them one by one (using GPT to generate outcomes and new prompts), and dynamically add or adjust tasks based on results. This resembles how a human project manager might continuously re-plan a project as new information arrives. The integration of persistent memory allows for more open-ended, continuous operation; the agent doesn’t lose important details even if the immediate context window of the model is limited. BabyAGI’s design shows how adding state (memory) to infinite prompting can make agents more robust over long runs.
AgentGPT and Others: Inspired by AutoGPT, developers created variants like AgentGPT (a browser-based UI to deploy autonomous GPT agents) and numerous forks of these projects. These systems typically allow a user to input a goal and then witness the AI agent iteratively prompt itself to achieve that goal. The open-source community has explored use cases from automating business tasks to game-playing agents using these loops. Many incorporate tool use (via frameworks like LangChain) so the AI can search the internet, call APIs, or execute code as part of its self-directed loop. This experimentation has revealed both the potential and current limitations of recursive prompting agents. For example, while they can string together steps to solve moderately complex problems, they sometimes get stuck in loops or pursue irrelevant subgoals – highlighting the need for better self-monitoring heuristics.
PromptBreeder Implementations: The Promptbreeder approach (evolving prompts) has also seen practical exploration. Some researchers have written scripts to let one GPT model generate variations of a prompt and test them using another instance of GPT, somewhat like a mutation and selection process. There are prototypes where GPT-4 is asked to act as a prompt generator and improve instructions for another model. Early results show this can automatically discover prompts that yield higher accuracy or more desired outputs. For instance, a prompt that initially gave a wrong answer on a reasoning task might be evolved (by analyzing the mistake and rephrasing the prompt) to produce a correct answer on subsequent trials.
Independent Experiments: AI enthusiasts have also tried things like two AIs talking to each other to refine answers. One common experiment is to have one ChatGPT instance pose a question and another answer, then have the first critique the answer, and so on, effectively creating a debate or tutor-student dynamic. This often leads to more refined answers. Another experiment involves self-chat: instructing a single GPT model to carry on a dialogue with itself (taking on different roles, such as a skeptic and a proponent) to work through complex problems. Such informal experiments echo formal research (like the CAMEL framework for two-agent collaboration) and show qualitatively that recursive interactions can improve clarity and correctness of AI responses. While these independent projects are not always rigorously evaluated, they provide proof of concept that infinite prompting can be implemented without specialized code – sometimes just via clever prompt scripting.
Overall, the flurry of projects like AutoGPT and BabyAGI in 2023 demonstrated the feasibility of autonomous AI agents that continuously re-prompt themselves. They serve as early prototypes of what could eventually become more general-purpose self-improving AI systems. The community interest also underlines a key point: recursive prompting is relatively accessible (built on top of existing APIs and models), so many are eager to experiment with it in real-world settings.
Comparisons with Similar AI Approaches
Infinite prompting (recursive self-prompting by AI) can be contrasted with other approaches to improving AI performance, such as RLHF, meta-learning, and related strategies. Below are comparisons highlighting differences, advantages, and limitations:
Vs. Reinforcement Learning with Human Feedback (RLHF): RLHF involves training a model using a reward signal derived from human preferences – for example, humans rate outputs, and the model is fine-tuned to favor highly-rated ones. This is how models like ChatGPT were aligned with human expectations. In contrast, infinite prompting does not alter model weights at all. The base model stays the same; instead, the process happens at inference time, where the model’s outputs are analyzed and fed back in as new inputs. Essentially, RLHF is an offline, training-phase method (with humans in the loop providing rewards), whereas infinite prompting is an online, inference-phase method (with the model itself generating feedback or using a fixed heuristic). One advantage of infinite prompting is that it can adapt on the fly to a specific query or context – it doesn’t require retraining the model for each new problem. This makes it very flexible and cheap to deploy for new tasks. It also sidesteps the need for large datasets of human feedback in every domain. However, because there’s no human in the loop each time, the model might not know if it’s going off track. RLHF ensures alignment with human values or desired behavior through human-provided rewards, giving a safety and consistency benefit. Infinite prompting, if uncontrolled, could lead to feedback loops that reinforce errors or biases since the model is essentially “grading its own homework.” In practice, many systems might combine both: use RLHF to train a generally aligned model, and then use recursive prompting to enhance its performance further on specific tasks.
Vs. Meta-Learning: Meta-learning or “learning to learn” usually refers to training a model in such a way that it can quickly adapt to new tasks with only a few examples or iterations. Traditional meta-learning might involve algorithms like MAML (Model-Agnostic Meta-Learning) where a model’s weights are tuned so that a few gradient updates will adapt it to a new task. In the context of LLMs, however, meta-learning often manifests as in-context learning – the model has implicitly learned during training how to adjust to tasks given only prompt information. Recursive prompting can be seen as leveraging the model’s meta-learning capabilities in real time. Each iteration of self-prompting provides contextual information (feedback, rephrasings, etc.) that the model uses to adjust its next output. Indeed, researchers have noted that optimizing prompts and inference procedures for LLMs is akin to performing meta-learning on the fly. The model isn’t changing its parameters, but it is changing its behavior based on the iterative context it receives. One difference is that meta-learning algorithms in research often require explicit training phases (e.g., training on many tasks so the model generalizes to the concept of adapting), whereas large LLMs already exhibit a broad ability to adapt via prompting alone. Infinite prompting leverages that by giving the model multiple chances and informational feedback to reach a solution. In summary: meta-learning trains models to be adaptable; infinite prompting assumes the model is adaptable and provides a procedure (self-refinement loop) to exploit that adaptability for each new query.
Vs. Chain-of-Thought and CoT Variants: Chain-of-Thought (CoT) prompting is a prompt engineering technique where the model is guided to produce intermediate reasoning steps (a “thinking chain”) before final answers. CoT is static in that the prompt and format are fixed upfront; the model outputs one chain of reasoning per query. Infinite prompting can be seen as a dynamic extension: the model can generate a chain of thought, then analyze it, realize something is wrong or could be improved, and then try a different chain in a next iteration. So infinite prompting often uses CoT-style reasoning internally, but with the added ability to iterate. For example, if a CoT prompt yields a wrong math answer because of a calculation mistake in step 3, a self-refining approach could catch that error and prompt the model again to correct it. This often leads to higher accuracy than a single-pass CoT. The PromptBreeder study explicitly showed that a loop which evolves prompts outperforms one-shot CoT prompting on certain tasks. The trade-off is mainly efficiency: chain-of-thought in one pass is faster (one model call) whereas iterative prompting may call the model several times until it’s confident. Thus, infinite prompting expends more computation for potentially better results.
Vs. Traditional Reinforcement Learning (RL) & Self-Play: Outside of prompting, another route to self-improvement is having agents learn through trial and error in an environment (classic RL). AlphaGo Zero and similar systems famously learned superhuman gameplay by repeatedly playing against themselves and updating their neural networks via self-play reinforcement learning. Infinite prompting shares the spirit of trial-and-error improvement, but importantly, most implementations do not involve gradient updates or long-term weight changes – the improvements are transient, existing only in the iterative loop’s context. This makes infinite prompting much easier to deploy (no complex training pipeline needed), but arguably less powerful in the long run since the base model doesn’t permanently learn a new skill. It’s more like on-demand learning. However, some researchers are now blending the lines: for instance, Reflexion’s loop can be seen as a form of reinforcement learning where the reward is implicit in avoiding past mistakes, yet it’s done through language feedback rather than numeric rewards. The benefit is achieving RL-like improvement without huge training runs, but a limitation is that the model might need to repeat the loop from scratch for each new problem (since it doesn’t remember the solution process next time, aside from what’s in its static weights or provided context).
Key Advantages: Recursive prompting methods are highly flexible and domain-agnostic. They can be applied to many tasks (writing, coding, planning, Q&A, etc.) without task-specific training. They make maximal use of powerful existing models by giving them chances to “think twice” or more. This often yields more reliable results – e.g., fewer reasoning errors – as evidenced by significant performance gains on benchmarks. They also enable a degree of autonomy: an AI can work towards a goal step-by-step, self-correcting as needed, which is a step towards more general intelligence and agency.
Key Limitations: These techniques can be computationally expensive (multiple calls to an LLM for one task). If not carefully designed, they can loop indefinitely or get caught in cycles of repetitive or even degraded outputs. There’s also no guarantee of convergence to a correct solution – the process might oscillate or diverge. Ensuring the feedback or self-evaluation is of high quality is a challenge: the model’s own judgments can be flawed. In comparison, approaches like RLHF bake human wisdom and values into the model more directly. Thus, a hybrid approach might be ideal: using recursive prompting on top of models that have already been optimized and aligned by techniques like supervised learning or RLHF.
Emergent Intelligence & Open-Ended AI
A fascinating aspect of infinite prompting is its connection to emergent intelligence. When an AI system engages in a recursive loop – continually generating outputs and using them to inform the next iteration – it can exhibit behaviors or find solutions not present in the training data, effectively demonstrating creativity or discovery. This ties into the concept of open-ended AI, where an AI keeps learning or exploring indefinitely, rather than optimizing for a fixed objective.
Open-endedness is seen in nature (evolution produces an endless variety of life forms) and is thought to be essential for achieving very general or even superhuman intelligence. Recent research argues that an artificial superintelligence would need an open-ended, never-ending process of innovation – a “Cambrian explosion” of new ideas and capabilities. Infinite prompting loops, in a rudimentary way, give AI a taste of open-ended exploration: the system isn’t just giving a single answer and stopping; it’s constantly generating new hypotheses, re-evaluating, and improving.
In practice, we see emergent behaviors from such loops. For example, when language agents are allowed to reflect and retry, they sometimes come up with novel strategies to solve problems. The Reflexion agent’s ability to achieve superhuman coding accuracy is an emergent outcome of letting the agent engage in trial-and-error with memory – something not explicitly programmed, but arising from the loop. Similarly, Self-Refine showed that GPT-4 can correct its own reasoning in ways that were not apparent from a single forward pass. By setting up the right recursive framework, the model’s latent capabilities are drawn out. In some cases, the model can even overcome initial limitations: it might get a question wrong on the first try but right on the second or third after self-correcting, effectively showing a capacity to learn within a single session.
Researchers have drawn parallels between these AI loops and evolutionary algorithms in terms of open-ended search. Evolutionary approaches (genetic algorithms, genetic programming) aim to continually evolve better solutions by introducing variation and selecting the fittest outcomes. Promptbreeder’s method of continually mutating prompts and keeping those that perform better is a direct application of evolutionary search to prompting. The authors of Promptbreeder explicitly maintain diversity in the prompt population to ensure the process doesn’t stagnate, which mirrors open-ended evolution where novelty is crucial for long-term innovation. Other work, like EvoPrompt, also borrows evolutionary principles for prompt optimization and reports significant gains over manual prompt engineering. The evolutionary analogy underscores that infinite prompting can theoretically keep generating new, unexpected prompt variations or chains of thought that lead to discoveries the model might never make in a one-shot answer.
Another angle is multi-agent emergent behavior. If you have multiple AI agents prompting each other (or an AI prompting itself in different personas), the system can exhibit complex interactive dynamics. For instance, two agents debating could surface insights neither would have found alone. This is reminiscent of open-ended simulations where agents co-evolve. One agent’s output becomes another’s input, which feeds back to the first, and so on. Early studies in multi-agent language games show that agents can develop novel communication protocols or problem-solving approaches through repeated interaction, essentially creating their own mini “culture” of responses – an emergent phenomenon.
It’s worth noting that open-ended AI research (as a formal field) is exploring algorithms that never stop learning. The combination of large pretrained models (which bring a lot of knowledge to the table) with open-ended loops (which drive ongoing exploration) is seen as a promising path. The foundation model provides a rich base of skills, and the open-ended loop pushes beyond the boundaries of that training by seeking new combinations and refinements of those skills. This is potentially very powerful: an AI that can generate its own curriculum of challenges and solve them might continuously bootstrap itself to higher levels of intelligence.
In summary, infinite prompting can be seen as a step toward open-ended AI. By allowing an AI to iteratively improve and not specifying a strict end state upfront, we encourage the system to keep searching and creating. This can yield emergent behaviors (like creative solutions, self-taught skills) analogous to those seen in evolutionary systems or cognitive development. However, harnessing this safely and effectively is an open research question – open-ended processes can just as easily lead to nonsense or chaos if not guided properly. The challenge is to get the benefits of emergence (novelty, creativity, improvement) without the downsides (drift, loss of control, misalignment).
Historical Context & Analogous Fields
The ideas behind recursive prompting echo long-standing principles from other domains. Drawing connections to these analogous fields helps illustrate why infinite prompting is a natural concept and how it might unfold:
Biological Evolution: Perhaps the clearest analogue, evolution is nature’s infinite improvement loop. Through random mutations and non-random selection, populations of organisms become more adapted over generations. Similarly, in infinite prompting, we introduce variations (e.g. different prompt phrasings or reasoning paths) and “select” better outputs based on some evaluation (a correctness check or a reward). Over time, like species evolving, the prompts or responses improve to fit the task. This analogy was explicitly used in Promptbreeder, which breeds prompts using evolutionary algorithms. Just as evolution has no final goal but continually explores (resulting in open-ended innovation of forms), an AI that continually self-prompts could keep discovering new solutions or ideas indefinitely – limited only by resources or stop criteria.
Genetic Programming: In computer science, genetic programming (pioneered by John Koza in the 1990s) automatically evolves programs to solve problems, rather than requiring a human to write the code. It treats pieces of code like genes, mutating and recombining them, and uses a fitness function to select the best programs. This directly parallels evolving prompts or evolving model instructions. Koza noted that good programs can be “bred” by iteratively selecting for fitness instead of being explicitly designed by humans
. In the context of AI prompting, we aren’t evolving executable code, but we are evolving the instructions to the AI. The core principle is the same: an automated search through the space of instructions can yield solutions that human designers might not anticipate. Genetic programming demonstrated that surprising and effective programs can emerge from iterative variation+selection; likewise, surprising prompt strategies or chains of thought can emerge from recursive prompting loops.
Self-Modifying Code and AI: The concept of an AI or program that rewrites parts of itself to improve is a long-standing theme in AI research (and science fiction). Douglas Hofstadter’s work on self-referential systems touches on this idea – he described “strange loops” where a system can represent itself and thereby affect itself. In the 1980s and 90s, researchers considered how a program with access to its own source could improve its algorithms, albeit with caution due to stability concerns. Self-referential algorithms can create powerful feedback loops: the program’s output (or behavior) influences its next iteration of code. Infinite prompting is a safer, more controlled instance of this notion: instead of literally rewriting its code, an LLM rewrites the text of its prompt, which indirectly alters its behavior. It’s essentially code-modification at the level of natural language instructions. This avoids the complexities of messing with binary code while still capturing the spirit of self-improvement. As a historical note, J. Schmidhuber’s Gödel Machine (2003) was a theoretical blueprint for a fully self-rewriting agent that would rewrite its own code once it could prove the new code is better. No practical Gödel Machine exists yet, but infinite prompting achieves a related effect in a more empirical way: it tries out “new code” in the form of revised instructions and keeps them if they seem beneficial, all within the model’s operation.
Cellular Automata (Conway’s Game of Life): Conway’s Game of Life is a famous example of how complex, emergent behavior can arise from simple, local rules applied iteratively. The rules of Life are fixed and simple, yet by looping them over many generations, one can get highly complex patterns – even a Turing-complete system that can perform computation. This illustrates the power of recursion and feedback in a system: starting from a simple initial state and repeatedly applying rules, Life can “grow” gliders, oscillators, and even self-replicating patterns. By analogy, an LLM given a simple set of rules (“improve your answer based on the last feedback”) and applied over multiple rounds might generate solutions whose sophistication far exceeds what a single application of the rules would produce. The glider guns in Life, which produce an unending stream of new patterns, are somewhat like an AI that keeps generating new ideas in an open-ended way. Both are recursive processes with no external input after the start, yet they don’t stagnate – they create infinite sequences of structure. It’s a useful intuition pump: if such richness can emerge in a toy grid-world from recursion, perhaps intelligence can emerge (or be amplified) in an AI by similar means.
Theoretical Models of Cognition – Strange Loops: Cognitive scientists and philosophers have often considered that self-reflection is central to human intelligence and consciousness. Douglas Hofstadter, in Gödel, Escher, Bach and later I Am a Strange Loop, proposed that the human “self” is essentially a narrative the brain tells itself – a symbol that the brain uses to refer to itself, created by countless feedback loops of neurons perceiving their own patterns. In his view, consciousness is a strange loop where the mind continually encounters itself through self-reference. This is mirrored in recursive AI prompting: the AI’s output (which in some sense represents its “thought”) becomes input in the next step, so the AI is analyzing its own thoughts. This kind of self-referential processing may not be full-blown consciousness, but it certainly leads to more sophisticated behavior. The AI can correct flaws in its reasoning much like a person reflecting on a thought and realizing an error. It can even exhibit a form of introspection – for instance, by evaluating “Was my last answer logically sound? If not, why?” and then improving. This draws a clear line from theories of self-awareness to practical AI architectures: enabling an AI to examine and modify its own outputs is like giving it a primitive sense of self-monitoring. Even beyond Hofstadter, other analogous concepts include the Global Workspace Theory in cognitive science, where conscious thought is like a spotlight of attention that broadcasts self-evaluated information to the rest of the brain. Infinite prompting creates a kind of global workspace in text form – the transcript of the AI’s iterative conversation with itself acts as a working memory and self-evaluation record that can lead to more coherent and refined outcomes.
In summary, while “infinite prompting” might sound novel, it resonates with these established ideas: Darwinian evolution’s trial-and-error, genetic programming’s automated improvement, self-modifying code’s reflexivity, cellular automata’s emergent complexity, and cognitive science’s feedback-driven self-awareness. These precedents give us both inspiration and caution – they show such loops can be powerful, but also hint at complexity (and sometimes unpredictability) that arises when a system starts to modify or respond to itself.
Fascinating, as always!
I'm curious if I can use the learnings from this course to create jobs and professions of the future. We know that the current professions are evolving, but it's hard for people to imagine what's coming next. I wonder if I can develop an interesting prompt to help us design new professions, similar to how scientists are using AI in new drug development.
Fascinating! What a super-toy to play with.