

Video Source: Simons Institute / Speaker: OpenAI researcher, Sebastien Bubeck
The advancement of AI continues at a profound pace in 2025.
Keeping up with the announcements is hard. Keeping up with the implications of those announcements is even harder.
The goal of this article is to share the most profound implication of January’s biggest AI breakthrough as it relates to how knowledge workers and thought leaders prompt AI.
To set the context, let’s go back to September…
How OpenAI Began The Era Of AI Inference Scaling
On September 12, 2024, OpenAI released o1-preview.
Before the launch of this model, the progress of frontier AI models was based on the Pre-training Scaling Law:
Pre-training Scaling Law: As you increase the compute, parameters, and data, the quality of the models improved at an exponential and predictable rate.
You can think of this pre-training scaling law as Moore’s Law of AI. Moore’s Law took us from mainframe computers that fill up entire rooms to supercomputers that fit into your pocket just a few decades later. The Pre-training Scaling Law is more profound and is happening faster.
With the release of OpenAI’s o1 model, we see the beginning of a new scaling law that stacks on top of Moore’s Law and the AI Pre-Training Scaling Law. Here it is in a nutshell.
Inference Scaling Law: As you scale the amount of time you allow models to think before responding, the smarter they become.
To put this in context, Noam Brown, who is in charge of scaling OpenAI’s o1 series of models, explains:
"The fact that we're able to have this different dimension for scaling that is so far pretty untapped I think is a big deal. And I think means that the ceiling is a lot higher than a lot of people have appreciated."
Seeing the three scaling laws (Moore’s Law, the AI Pre-training Scaling Law, and the Inference Scaling Law) stacking on top of each other multiplicatively, I wrote in late September:

These scaling laws are complementary to each other because:
Better compute (Moore’s Law) makes it cheaper and faster for models to think (Infererence Scaling Law).
Better compute (Moore’s Law) makes it cheaper to pre-train models with more parameters and data (Pre-Training Scaling Law).
Better pre-training (Pre-Training Scaling Law) improves the quality of AI reasoning (Inference Scaling Law)
Better thinking (Inference Scaling Law) creates high-quality synthetic data that helps pre-train the models (Pre-Training Scaling Law).
Now that we understand the Inference Scaling Law and how it relates to the other scaling laws, let’s explore what makes the Inference Scaling Law so special…
What Makes Inference Scaling Special Beyond Speeding Up The Pace Of AI
The following video clip that I curated captures some of the most important nuances about the o1 series of models that many overlook:
Source: OpenAI's Noam Brown, Ilge Akkaya and Hunter Lightman on o1 and Teaching LLMs to Reason Better
To understand o1's significance, it's helpful to understand two types of human thinking, which Nobel Laureate Daniel Kahneman explained in his book Thinking Fast And Slow:
System 1 (Fast Thinking):
Quick, instinctive responses
Pattern recognition
Automatic reactions
Based on familiar experiences
Example: Instantly recognizing a friend's face or answering "What's the capital of France?"
System 2 (Slow Thinking):
Deliberate, logical reasoning
Step-by-step analysis
Careful consideration
Handling novel situations
Example: Solving a complex math problem or designing a new business strategy
Previous AI models excelled at System 1 fast thinking but struggled with System 2. As Noam Brown explains:
"For some tasks, You don't really benefit from more thinking time. So if I ask you like what's the capital of Bhutan, you know You can think about it for two years. It's not gonna help you get it right with higher accuracy... [But] there's some problems where there's clearly a benefit from being able to think for longer."
o1 represents the first AI model specifically designed for System 2 thinking.
With this deeper understanding of Inference Scaling, let’s explore three of its deeper implications…
Understanding what problems benefit from extra thinking time could be a competitive advantage
The Inference Scaling law iterates faster than the Pre-Training Scaling Law
The AI models are building their own unique form of reasoning
#1. Understanding What Problems Benefit From Extra Thinking Time Could Be A Competitive Advantage
Most situations don’t require extra thinking. For example, if I asked AI for the capital of the United States, having extra thinking time wouldn’t be helpful. AI could immediately give the right answer 100% of the time.
But, there are other situations, like scientific discovery, where more thinking time, such as hours or days, could lead to breakthroughs.
Being one of the first people to identify a complex, important problem in their field that would benefit from extra thinking time could potentially be a breakthrough opportunity for someone’s career.
Fortunately, there is a framework for identifying these problems. In the video above, Noam Brown introduces the Generator-Verifier Gap.
“You might call it a generator-verifier gap where it’s really hard to generate a correct solution, but it’s much easier to recognize when you have one. And I think all problems exist on this spectrum from really easy to verify relative to generation like a Sudoku puzzle versus just as hard to verify as to generate a solution like name the capital of Bhutan.”
—Noam Brown
Given that understanding when and how to use extra AI thinking time is so important, it’s worth going deeper into the Generator-Verifier Gap. Noam does just that in another talk he delivered in late 2024:
Source: Simons Institute
Putting the Generator-Verifier Gap in layman’s terms, today’s thinking models are particularly well-suited for problems that are easy to verify and hard to generate a solution to. A problem is easy to verify when:
You can instantly tell if it's right (like seeing all sides of a solved Rubik's cube match)
You have clear criteria for success (like checking if numbers add up correctly)
You can test the solution quickly (like running code to see if it works)
You have an objective way to measure success (like seeing if a bridge stays standing)
A problem is hard to generate solutions for when:
There are tons of possible combinations to try (like all the ways you could turn a Rubik's cube)
Small mistakes can ruin everything (like one wrong move in chess)
You need to plan many steps ahead (like solving a complex math proof)
Multiple pieces need to fit together perfectly (like designing a complex machine)
For example…
It's easy to check if a password is secure, but hard to crack one
It's easy to verify a math proof is correct, but hard to come up with one
It's easy to tell if a joke is funny, but hard to write a good one
It's easy to recognize a well-designed product, but hard to design one
Now, let’s move to a real case study that shows how this knowledge can be your competitive advantage
The world’s largest company is already using it to explore the search space of potential chip designs and find designs that are 5x better. The founder and CEO of Nvidia, Jensen Huang, explains the breakthrough in the clip below:
Source: No Priors Podcast
In the end, the Generator-Verifier Gap suggests that some of the following domains might be impacted by extra thinking time first…
Application #1. Complex Scientific Analysis:
Healthcare researchers using o1 for cell sequencing data annotation
Physicists generating mathematical formulas for quantum optics
Systematic exploration of research hypotheses
Application #2. Advanced Mathematical Reasoning:
Solving IMO-level math problems
Complex geometric proofs
Multi-step mathematical derivations
Application #3. Sophisticated Programming:
High-level competitive programming problems
Complex system design
Multi-step debugging and optimization
Application #4. Multi-Step Workflows:
Breaking down complex tasks
Managing dependencies
Handling edge cases systematically
And, as it relates to knowledge workers, entrepreneurs, and thought leaders…
Strategic analysis & decision making
Innovation and idea generation
Pattern recognition across domains
Mental model development
Opportunity space mapping
Complex system design
These capabilities are particularly valuable because they:
Address high-value knowledge work activities
Benefit from systematic exploration
Require transparent reasoning
Create compound value through combination
All and all, these capabilities could accelerate complex analysis, improve decision-making, and enable novel innovations.
#2: The Inference Scaling Law Iterates Faster Than The Pre-Training Scaling Law
OpenAI went from GPT-1 to GPT-4 over 5 years:

In just three months, from September 12 to December 20, OpenAI went through three generations of its o1 series:

And with each generation, significant improvements happened:

To put these charts in context:
SWE-bench is a benchmarking tool that measures the skills of a Software Engineer (SWE) in areas like coding, algorithms, and problem-solving.
You can see a significant increase in model performance between generations.
The time between models is months rather than years.
71.7% accuracy means the AI model is more accurate than most competent professional programmers.
Software is one of the largest and fastest-growing industries in the world.
This rapid iteration points to the possibility that we may see much AI progress faster in the short term.
More importantly, let’s explore the next level…
#3: The AI Models Are Building Their Own Unique Form Of Reasoning
In the video at the top of this post, we see a senior OpenAI researcher, Sebastien Bubeck, say something profound that I will unpack:
“Everything is kind of emergent. Nothing is hard-coded. Anything that you see out there with the reasoning, nothing has been done to say to the model, “Hey! You should maybe verify your solution. You should backtrack. You should X, Y, Z.” No tactic was given to the model. Everything is emergent. Everything is learned through reinforcement learning. This is insane, insanity.”
Said in plain English:
The AI developed its own methods of advanced thinking and problem-solving.
No human programmed it with specific strategies like "check your work" or "try a different approach if stuck".
Instead, through reinforcement learning (trial and error), it discovered these strategies on its own.
The AI effectively taught itself how to think systematically.
Here’s why this is insane:
It's unprecedented that an AI could develop sophisticated reasoning strategies without being explicitly taught them.
It challenges our assumptions about needing to teach AI step-by-step logical thinking.
The AI found effective ways to break down and solve problems that humans didn't anticipate or design.
AI could be teaching us about reasoning pretty soon rather than the other way around.
Given that I have intensively studied successful thinking patterns over the last 7 years, I’m particularly excited by thinking models, and my spider senses tell me that it’s very significant not just for more advanced AI, but for more advanced human reasoning. More on this later in the article.
Now, we are in the meat of what I wanted to get to. Everything before this point was the preamble.
Now that we understand the significance of OpenAI’s o1 series and the Inference Scaling Law let’s talk about the big January news.
A company based in China released a model that is similar to OpenAI’s o1 series in that it thinks it is better on several dimensions…
This New Model Is Getting Everyone In Silicon Valley Talking

On January 20, unknown AI frontier model company DeepSeek released a game-changing new model called R1.
And the whole AI field is going crazy about it. For example, below is an X post from Marc Andreessen, the founder of Netscape and one of the largest venture capital investors in the world:
Realizing the importance of this release, I decided to read dozens of the best articles on the topic, synthesize what I learned, explore the second-order effects, and then simplify everything so you could rapidly get the key points.
Here are the 9 keys to understanding why this model is so important:
R1 outcompetes OpenAI’s o1 model on key benchmarks
R1 is 30x cheaper to use than OpenAI’s o1 model
R1 is open source
R1 is twice as fast as OpenAI’s o1 model
DeepSeek is based in China
R1 is small enough to run locally
Users can see AI’s full chain of thought for the first time
R1 Zero developed advanced reasoning on its own
The thinking Of R1 Zero was hard for humans to understand
If you’re already aware of R1, I recommend skipping to point #7, where I explore R1’s synthetic reasoning at a deeper level than I have seen written about anywhere else.
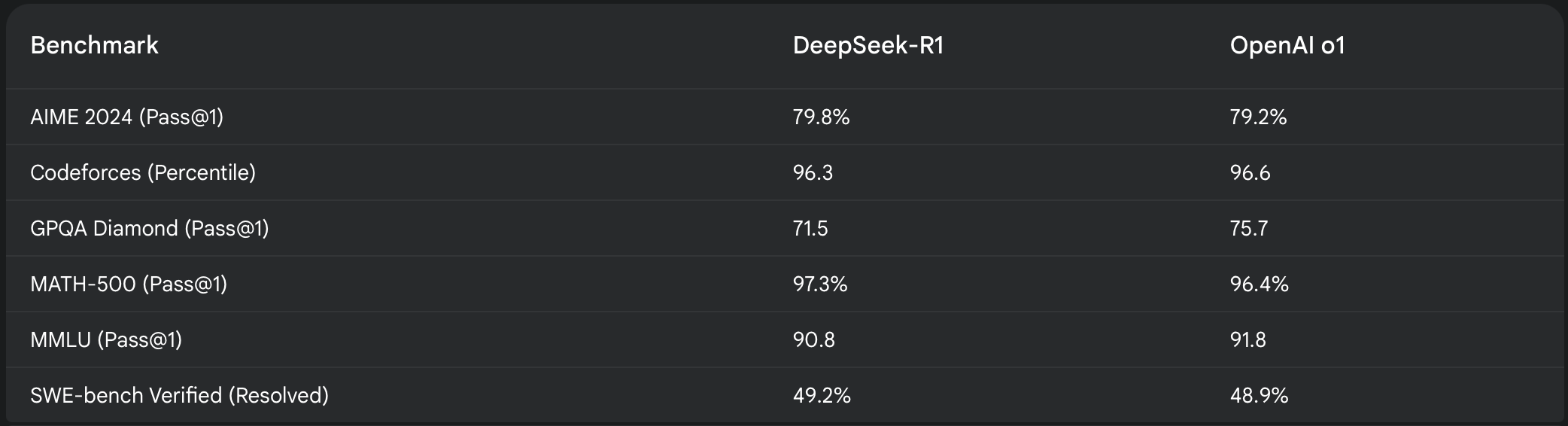
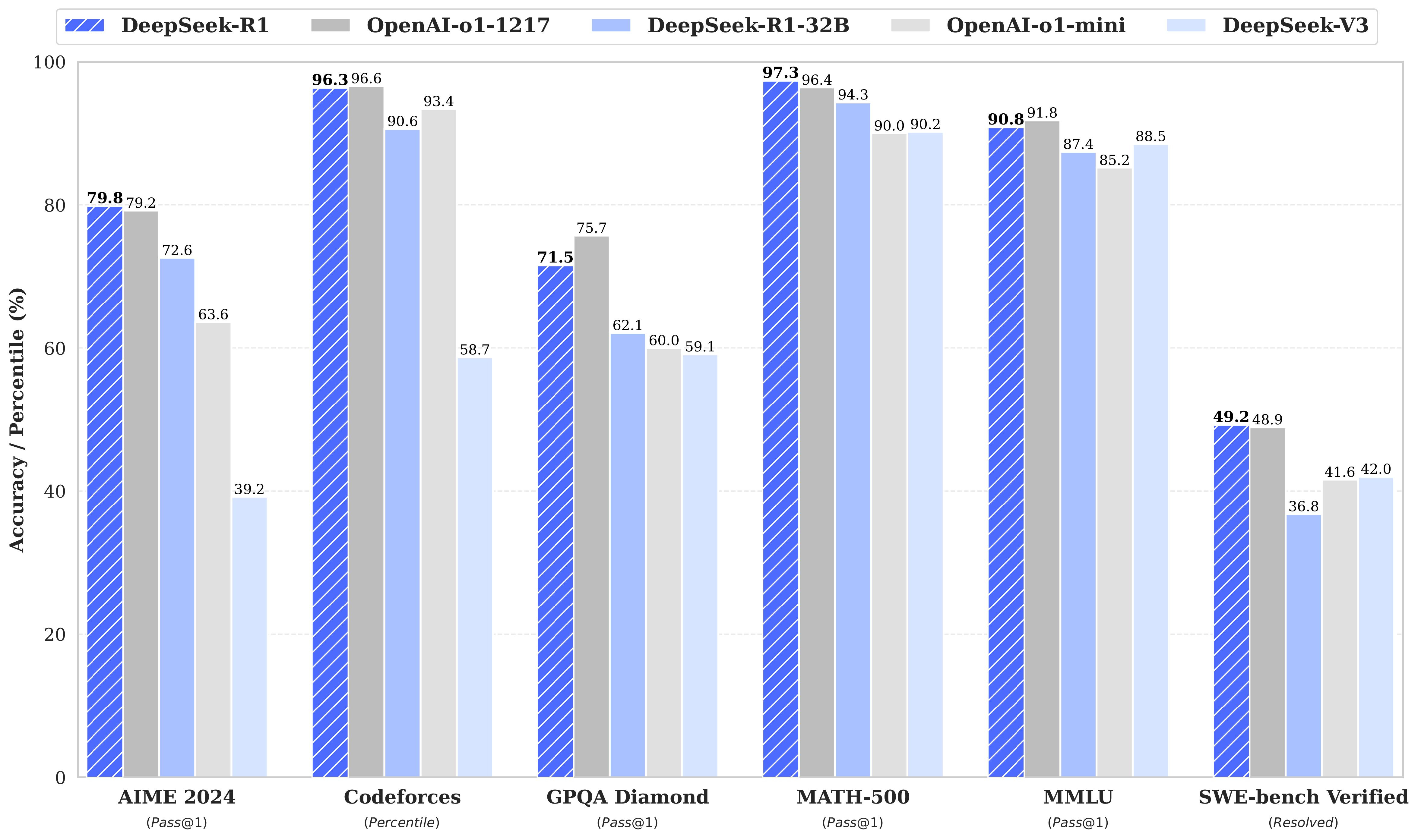
#1. R1 outcompetes OpenAI’s o1 model on key benchmarks
Below are the key results from benchmarks comparing o1 and R1:
#2. R1 is 30x cheaper to use than OpenAI’s o1 model

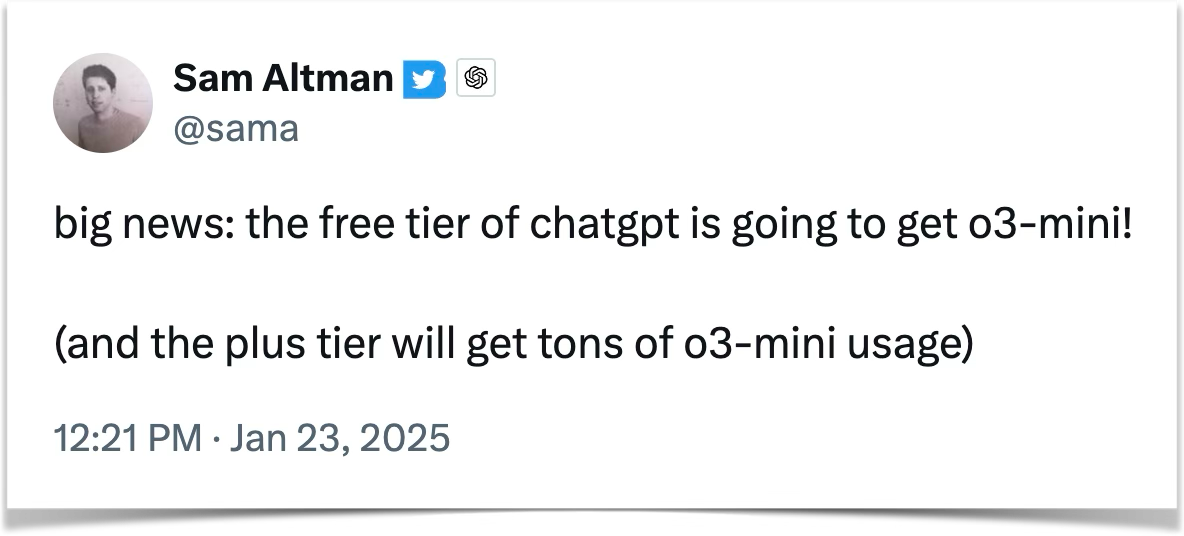
The fact that R1 is 30x cheaper than o1 has many implications.
First, the huge price differential puts competitive pressure on OpenaAI.
Just a week after R1’s launch, likely in reaction to R1, Sam Altman, CEO of OpenAI, announced that o3-mini will be available for free:
And, he also stated that OpenAI will pull forward the release date of their forthcoming model:

Secondly, cheaper inference means smarter AI. Having cheaper inference means that users can afford to let the model think for longer to improve the quality of its responses.
#3. R1 is open source
Below is an X post from a Sr. Research Manager at NVIDIA that contextualizes the significance of R1 being open-source:

And, it’s not just significant that DeepSeek is open-source. It is significant that DeepSeek is open-source and that it caught up with the leading closed models in performance.

R1 being open-source is a big deal on many levels:
#1. Researchers across the world at academic institutions can now do deeper research on leading AI models.

We can already see this happening with multiple teams replicating the results:
#2. Developers around the world can edit and build upon it without working at a leading lab.
Open-source developers are already connecting the model to new capabilities:
The implications of having a leading AI model that is open source are significant:
Innovation: It’s a democratizing force that will lead to faster innovation in the short term.
AI Safety: It increases AI safety risk since anyone in the world with limited resources can create powerful models designed to cause damage in the long term.
Competition: It’s particularly a big deal to Meta because it previously had the leading open-source model (Llama):
#4. R1 is twice as fast as OpenAI’s o1 model
The graph below shows how R1 is not just 30x cheaper, but also twice as fast…

#5. DeepSeek is based in China
The future of geopolitical power rests on who gets to advanced AI first. To this end, the US government has attempted to stall AI’s chip industry in any way it can:

The DeepSeek model is the first one outside the US that has surpassed leading US AI companies on certain key levels. Not only that, it shows that the Chinese chip ban alone may not be enough to accomplish the US’ goal of AI dominance.
In addition to the impact of AI on geopolitical power, many are concerned that if a leading AI is from China, it will express biases and censor areas that are related to topics sensitive to the Chinese government.
All and all, some are calling it the ‘Chinese Sputnik’ moment.
#6. R1 is small enough to run locally
Users can run distilled versions of the model on their computers. This means you can:
Use it for free
Get faster responses
Keep your data private
Customize the model at a deeper level
The video below shows you how to set it up on your computer in just a few minutes:
This development directly benefits device manufacturers as it could drive “the biggest PC and smartphone upgrade cycle we have ever seen.” [Gavin Baker]
#7. Users can see AI’s full chain of thought for the first time (this one is most relevant to knowledge workers)
When you use OpenAI’s o1 model, you can see a summary of the thoughts it had in order to develop its response to you.
With DeepSeek R1, you can see its full chain of thought.
To put this in context, imagine being able to hear every single one of someone’s thoughts when you communicate with them:
You would have much more context from which to interpret them.
If there was a miscommunication, you would be able to understand the root cause.
Rather than just talking about each other responses, you could talk about each other’s thinking processes.
Alternatively, below are other metaphors that helped me understand the potential of transparent synthetic reasoning:
Its thinking unfolds like watching a detective solve a case rather than just hearing the verdict. Every clue examined, every lead followed, every hypothesis tested. This detailed progression creates new possibilities for solving complex problems.
Think of reviewing a student's math test. Would you trust them more if they just wrote down the final answer, or if they showed all their work? For years, AI has been like that student who only writes down answers - leaving us to wonder how they got there.
Imagine having a time machine for your brain. When faced with a difficult challenge, you could spend years exploring every possibility, testing every hypothesis, and examining every angle – but still return to the present moment to make your decision. That's what R1's "thinking time" capability could represent in the future.
Imagine a chess grandmaster who could pause time at each move, spend years analyzing every possible sequence, and then resume play with that deeper understanding. But here's what will make future models like R1 even more powerful: while analyzing chess moves, it might discover principles that apply to military strategy, business competition, or resource allocation. Every exploration potentially yields insights far beyond its original purpose.
This is a big deal. Below are several examples of why:
Prompt troubleshooting becomes easier: When you get disappointing responses, you’ll be able to quickly troubleshoot the exact root cause rather than guessing why a black box gave a response. For example, you might see AI start with correct premises but make a logical leap at step 4. You can then point out this error to the AI and iterate from there.
Thinking patterns become key: When AI solves problems well, you can study its exact cognitive process. For example, you might notice that AI performs better when it lists assumptions first. Based on this observation, you might encourage it to list its assumptions in future prompts.
Prompt engineering evolves: This previews a future where understanding meta-cognitive strategies becomes a fundamental skill of prompt engineering. Prompt engineers might develop new techniques to guide the reasoning process step-by-step, making their role more about steering the thought process rather than just eliciting answers.
AI-To-AI collaboration deepens: In the future, there will likely be significantly more communication between AIs than between humans and AI. Therefore, some of the most significant impacts of transparent thought might appear in AI-to-AI communication. For example:
AIs could share and combine successful reasoning strategies with each other.
When one AI discovers a better way of thinking, all connected AIs could potentially benefit.
The most significant breakthroughs might come from unexpected combinations of thinking patterns.
There could be systems where multiple AIs critique each other's reasoning, with humans overseeing.
Better human problem-solving. Humans might start to internalize the AI's successful reasoning strategies, affecting how they approach problems. This could lead to improved human problem-solving skills.
AI safety could become easier and harder. On the one hand, transparency helps AI safety researchers build better approaches to alignment. On the other hand, it could make systems more vulnerable. If a prompt engineer can see the reasoning, they might find ways to exploit it, leading to new types of attacks or manipulations.
New types of AI safety: Current AI alignment focuses on matching outputs to human values. With visible reasoning, alignment could prioritize process alignment (e.g., "Does R1’s logic adhere to ethical heuristics at each step?") rather than just outcome alignment.
Better understanding of AI: At a fundamental level, how we use AI is mediated by our understanding of what AI is and what it can do. Understanding AI’s reasoning will help us understand AI better, creating new possibilities for using AI.
AI teaches us to think: AI could provide personalized learning experiences and explain complex concepts with step-by-step reasoning. Imagine a student struggling with a complex mathematical problem. R1 could not only provide the correct answer but also guide the student through the reasoning process, step-by-step.
New serendipitous discovery. Many discoveries in science and entrepreneurship happen serendipitously. As the individuals are trying to solve one problem, they generate insights into unrelated problems, notice unexpected connections between fields, or even develop new frameworks for thinking. Transparent reasoning could facilitate this serendipity.
#8. R1 Zero developed advanced reasoning on its own
DeepSeek also released R1 Zero, which was an experimental model trained purely through trial and error (reinforcement learning) with no human guidance. It just received feedback on whether its answers were right or wrong.
R1 is the refined, public version that started with some human examples of good reasoning before using reinforcement learning to improve further. Think of R1 Zero as the raw prodigy who figured things out alone but communicated oddly, while R1 is the polished version that combines natural learning abilities with proper communication skills learned from human examples.
What was amazing about R1 Zero is that it developed its own advanced reasoning abilities:

A group of researchers who replicated the results created the following chart to show how reasoning abilities emerged based on the number of training steps:
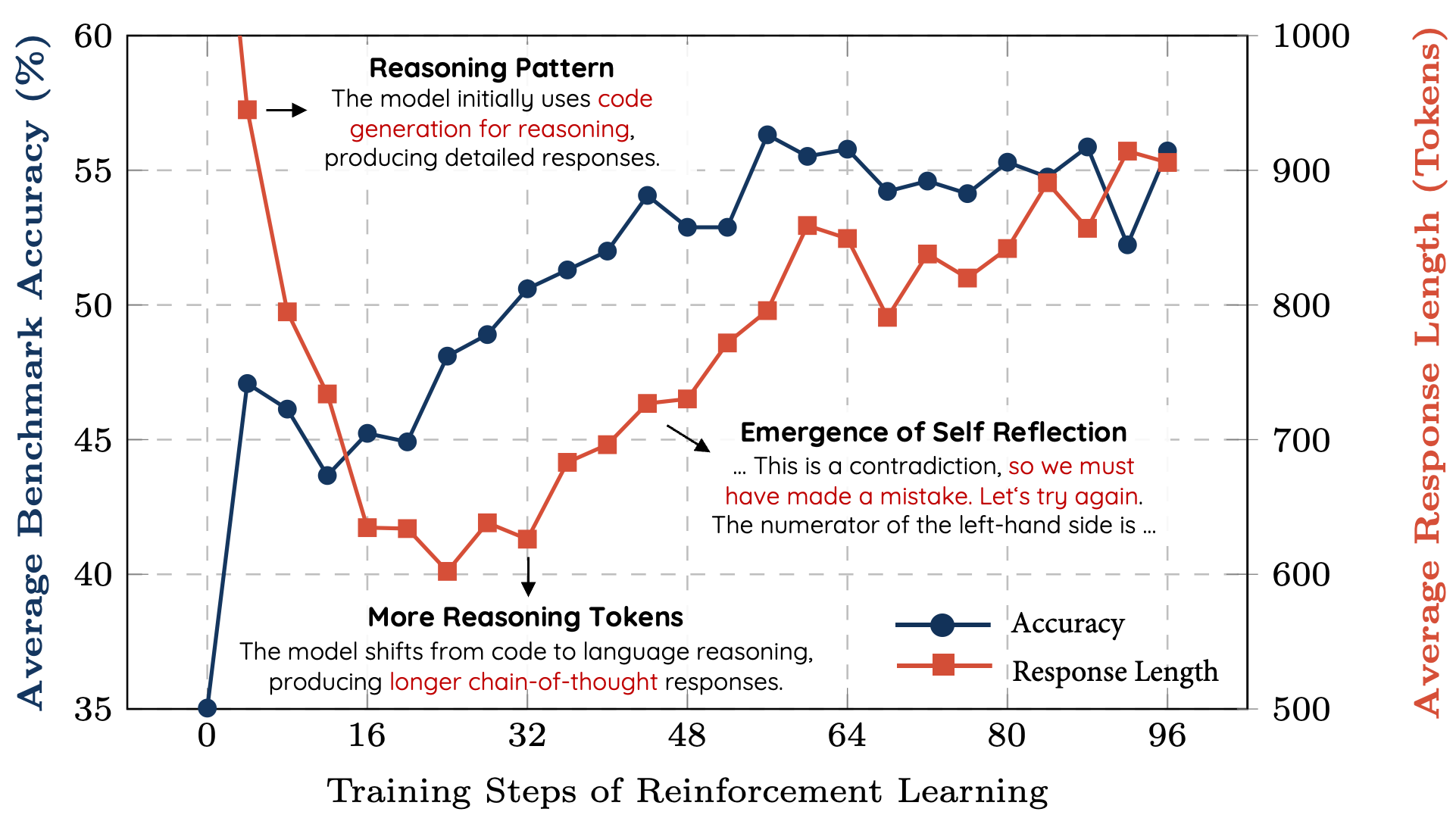
To understand why this is a big deal, think back to when AlphaGo (an AI built by Google) beat the Go world champion, Leed Sodol, for the first time back in 2016. A seminal point in the match was move 37, when AlphaGo made an extremely advanced move that had never been made before in Go.
Similar to how this famous move demonstrated novel strategic thinking beyond human convention, R1 Zero's development of reasoning abilities through pure trial and error marks a significant milestone in AI's capacity for independent learning. While AlphaGo discovered new approaches to Go by playing millions of games against itself, R1 Zero developed sophisticated problem-solving strategies through similar self-directed experimentation.
Just as Move 37 showed that AI could transcend centuries of human Go knowledge to find better solutions, R1 Zero's emergence of complex reasoning patterns - like verifying answers and trying alternative approaches when stuck - demonstrates that AI can develop advanced cognitive strategies without human guidance. Both cases suggest AI systems may be capable of discovering novel and effective approaches that humans haven't thought of or explicitly programmed.
DeepSeek-R1's development aligns with the "bitter lesson" in AI research, a concept put forth by AI pioneer Richard Sutton. This lesson suggests that, in the long run, general methods that leverage better learning methods and raw computational power are more effective than specialized, human-designed approaches.
DeepSeek-R1-Zero's reliance on pure reinforcement learning, allowing it to discover its own reasoning strategies through massive computational power, exemplifies this principle. This approach has yielded impressive results, suggesting that scaling computational power and allowing AI systems to learn independently may be a key to unlocking more advanced forms of AI.
As someone who has deeply studied metacognition for the last 7 years, I’m particularly curious about new ways of thinking that AI could help us learn faster and better.
#9. The thinking Of R1 Zero was hard for humans to understand
One other surprise from the R1 Zero is that some of the advanced problem-solving strategies that emerged and worked were hard for humans to understand or, as the researchers said, are "less human-interpretable".
This raises questions about the future of AI and whether the thinking processes of increasingly complex models will remain accessible to human understanding.
I find this point interesting as a prompt engineer. It makes me curious about there being ways that I could communicate with AI that are more effective.
Conclusion: Reflection Action & Insights
We are marching to AGI/ASI in the next few years
It’s critical to have an AGI strategy that reflects the magnitude of the change that’s coming
Play around with DeepSeek for a few hours
We are entering the era of synthetic reasoning
#1. We are marching to AGI/ASI in the next few years
Everything seems to point to the idea that AI progress is moving fast on multiple levels:
The three scaling laws (Moore’s Law, Pre-Training Scaling Law, & Inference Scaling Law)
The Convergence Effect (dozens of fields are contributing to the development of AGI)
The democratization of development (existence of a leading open-source model)
Increasing in scaling the investment (last week, a $500B AI infrastructure development plan was announced)
No one knows the exact timeline for AGI will be. But the top experts in the field are getting more and more confident that it will happen in the next 2-3 years. For example, below is a very telling recent video clip from Dario Amodei, the CEO of Anthropic (creator of Claude):
Source: WSJ
This video clip is telling because Dario tends to be very reserved in his predictions and not prone to hype.
#2. It’s critical to have an AGI strategy that reflects the magnitude of the change that’s coming
When changes happen in our environment, it’s critical to understand the depth of that change so we can mount the appropriate response.
If we think a change is small, but it’s actually enormous, then we risk being the people rearranging the chairs on the Titanic as it sinks. Said differently, we risk doing things that make us feel good, but in actuality, we’re just falling further and further behind.
The profundity of the possibility of AGI and ASI in the next 2-3 years is extremely hard to process. And given that the world hasn’t fundamentally changed yet, it’s easy to flinch away from the possibility of AGI and go on with life as normal.
I can relate to this flinching, and I have fallen prey to this tendency several times. But I think that it’s now more important than ever to gaze soberly into the possibility of AGI and plan accordingly.
At a base level, my basic suggestions to do first are as follows:
Put as much of your time into learning about AI so you can make more informed decisions about what to do about it.
When thinking about your life and career strategy, have a plan that accounts for the potential of human-level artificial general intelligence in the very near term.
I share my more detailed game plan for preparing for AGI in the paid perk section of my article: Convergence Effect: Why Artificial Superintelligence Will Arrive Faster Than Experts Predict.
#3. Play around with DeepSeek for a few hours
Dealing with major AI announcements can be difficult. There are so many happening that it can be overwhelming to pay attention to all of them.
Unfortunately, this overwhelm can easily lead to inaction and cause us to miss crucial developments.
This happened to me earlier this year.
Claude Sonnet 3.5 was released on June 20. Without even trying it out, I just assumed that it was basically the same as ChatGPT. I even tried out a few prompts, and it didn’t seem that different to me.
Fast forward to late August, I decided to really go all in and spend 10+ hours exploring it. Within a few hours, I started to have profound conversations with it, and I realized it was leagues beyond ChatGPT. Because it was so much better, I started getting way more value from AI.
On the one hand, two months isn’t a big deal, but in a world where AI is evolving at lightning speed, being late two months may have been like being late a year. Timing is crucial because being slightly ahead of the market can be a 1,000x difference in benefits than being slightly behind.
Now, when new advanced AI models come out, my recommendation is to spend a few hours using them yourself to build your own intuition and judgment.
I, for one, am using DeepSeek so I can understand how AIs think at a deeper level, so I can create better prompts no matter what model I’m using.
You can use DeepSeek for free at https://chat.deepseek.com.
Bottom line: We’re moving into a multi-model world where each model has different strengths, features, costs, response times, and personalities. The people who are most successful with AI will be the ones who understand the pros and cons of each model and how to use each one in the right situations.
#4. We are entering the era of synthetic reasoning
Dealing with AI models that can develop their own unique forms of reasoning represents a paradigm shift in how we interact with artificial intelligence. Just as AlphaGo's Move 37 showed us that AI could discover novel strategies humans hadn't considered in 2,500 years of Go, R1 Zero's emergence of independent reasoning capabilities hints at a future where AI systems might develop problem-solving approaches that transcend human cognitive patterns.
For knowledge workers and thought leaders, this means we need to evolve beyond traditional prompt engineering focused on getting the right outputs, to a deeper understanding of how to guide and interpret AI's reasoning processes. The most successful AI practitioners in the coming years won't just be those who can write the best prompts, but those who can effectively collaborate with and learn from AI's unique cognitive approaches.
Let me be more specific, knowledge work as we know it is limited in ways that are often invisible to us because we’re so used to them:
Limited by human cognitive bandwidth
Constrained by available time
Forced to take mental shortcuts
Solutions stay locked in specific domains
Knowledge work enhanced with transparent reasoning models that can think for minutes and days changes the game. It…
Leverages massive parallel processing
Explores exhaustive possibility spaces
Tests every promising approach
Discovers cross-domain applications
The implications transform how we even think about time.
Like having access to an alternate dimension where time moves differently for cognitive work, for the first time, we can:
Compress years of analysis into minutes
Test thousands of approaches simultaneously
Map entire possibility spaces systematically
Find solutions that would be impossible to discover under normal time constraints
Bottom line: Whether we're ready or not, synthetic reasoning is here, and it will challenge our fundamental assumptions about what it means to think and solve problems.
4 PAID SUBSCRIBER PERKS THAT 2X THE VALUE OF THE ARTICLE
Case Study: Creating A New Product With Synthetic Reasoning: One of the big challenges to using synthetic reasoning is knowing how to specifically prompt differently to capitalize on its capabilities. This hypothetical case study will help you.
Strategies And Prompts That Leverage R1’s Transparent Thinking: It’s still early days, but I’ve developed some prompting hacks with the support of Claude to tap into the power of transparent reasoning.
See An Example Conversation That Shows Off R1’s Thinking: I had a deep conversation with R1 to help me understand its transparent reasoning. I worked with Claude to develop the best prompts that would show off its implications the most, and the conversation was fascinating.
Go Deeper On R1 With These 10 Questions And 15 Articles: In this section, I share the top 15 deep-dive articles on R1 that I found so you can upload them to NotebookLM. Then, I provide you with 10 thought-provoking questions you can ask NotebookLM to get deeper insights into the implications.
To get access to all of these perks in addition to $2,500 in other perks, you just need to subscribe for $15/month.
